XPath实例
XPath 实例
在本节,让我们通过实例来学习一些基础的 XPath 语法。
1、🍇 XML 实例文档
我们将在下面的例子中使用这个 XML 文档。
XML 文档
<?xml version="1.0" encoding="ISO-8859-1"?>
<school1>
<class name="s1c1" desc="desc1 desc2 desc3">
<order>1</order>
<headTeacher>张三</headTeacher>
<student lv="1">
<name>Quber</name>
<age>33</age>
<email>qubernet@163.com</age>
</student>
<student lv="2">
<name>Jack</name>
<age>30</age>
<email>jack@gmail.com</age>
</student>
<student>
<name>Lili</name>
<age>26</age>
<email>lili@qq.com</age>
</student>
<student>
<name>Mali</name>
<age>24</age>
<email>mali@hotmail.com</age>
</student>
</class>
<class name="s1c2" desc="desc1">
<order>2</order>
<headTeacher>李四</headTeacher>
<student>
<name>XiaoMei</name>
<age>22</age>
<email>xiaomei@163.com</age>
</student>
<student>
<name>DongHua</name>
<age>24</age>
<email>donghua@gmail.com</age>
</student>
</class>
</school1>
<school2>
<class name="s2c1">
<order>1</order>
<headTeacher>王五</headTeacher>
<student>
<name>Jock</name>
<age>28</age>
<email>jock@163.com</age>
</student>
</class>
<class name="s2c2">
<order>2</order>
<headTeacher>赵六</headTeacher>
<student>
<name>HanMei</name>
<age>22</age>
<email>hanmei@163.com</age>
</student>
</class>
</school2>
2、🍈 实例说明
在下面的实例中,我们将使用.Net 的HtmlAgilityPack(官网地址:https://html-agility-pack.net/)组件进行演示。
HtmlAgilityPack 初始化代码
var demoHtmlStr = @"
<?xml version=""1.0"" encoding=""ISO-8859-1""?>
<school1>
<class name="s1c1">
<order>1</order>
<headTeacher>张三</headTeacher>
<student lv="1">
<name>Quber</name>
<age>33</age>
<email>qubernet@163.com</age>
</student>
<student lv="2">
<name>Jack</name>
<age>30</age>
<email>jack@gmail.com</age>
</student>
<student>
<name>Lili</name>
<age>26</age>
<email>lili@qq.com</age>
</student>
<student>
<name>Mali</name>
<age>24</age>
<email>mali@hotmail.com</age>
</student>
</class>
<class name="s1c2">
<order>2</order>
<headTeacher>李四</headTeacher>
<student>
<name>XiaoMei</name>
<age>22</age>
<email>xiaomei@163.com</age>
</student>
<student>
<name>DongHua</name>
<age>24</age>
<email>donghua@gmail.com</age>
</student>
</class>
</school1>
<school2>
<class name="s2c1">
<order>1</order>
<headTeacher>王五</headTeacher>
<student>
<name>Jock</name>
<age>28</age>
<email>jock@163.com</age>
</student>
</class>
<class name="s2c2">
<order>2</order>
<headTeacher>赵六</headTeacher>
<student>
<name>HanMei</name>
<age>22</age>
<email>hanmei@163.com</age>
</student>
</class>
</school2>
";
var doc = new HtmlDocument();
doc.LoadHtml(demoHtmlStr);
2.1、🍍 获取 school1 下所有子节点
school1
//获取school1下的所有子节点
var nodeSchool1Sons = doc.DocumentNode.SelectSingleNode("school1");
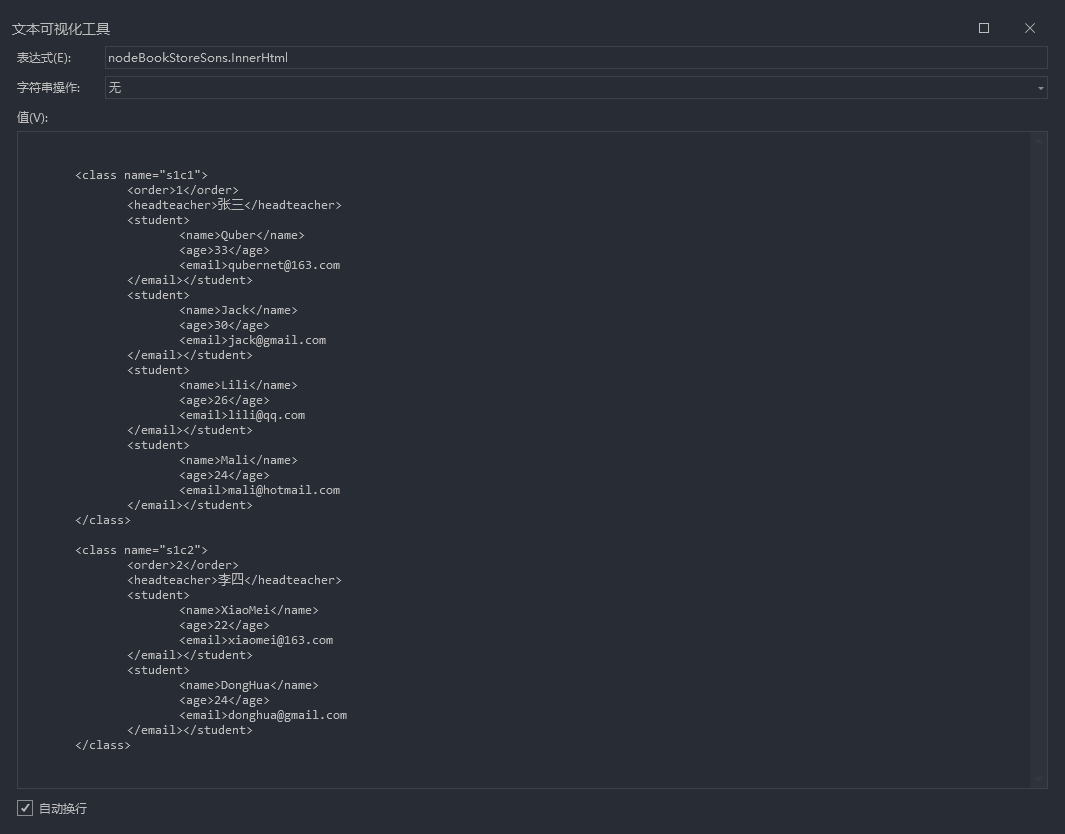
提示
上述中的school1,代表获取根目录或者某个节点下第一层的school1节点。
即:只能在第一层节点中去获取!!!
2.2、🥭 获取根节点 school1 下所有子节点
/school1
//获取根节点school1下的所有子节点(第二行等同)
var nodeSchool1RootSons = doc.DocumentNode.SelectSingleNode("/school1");
var nodeSchool1RootSonsEq = doc.DocumentNode.SelectNodes("/school1/*");
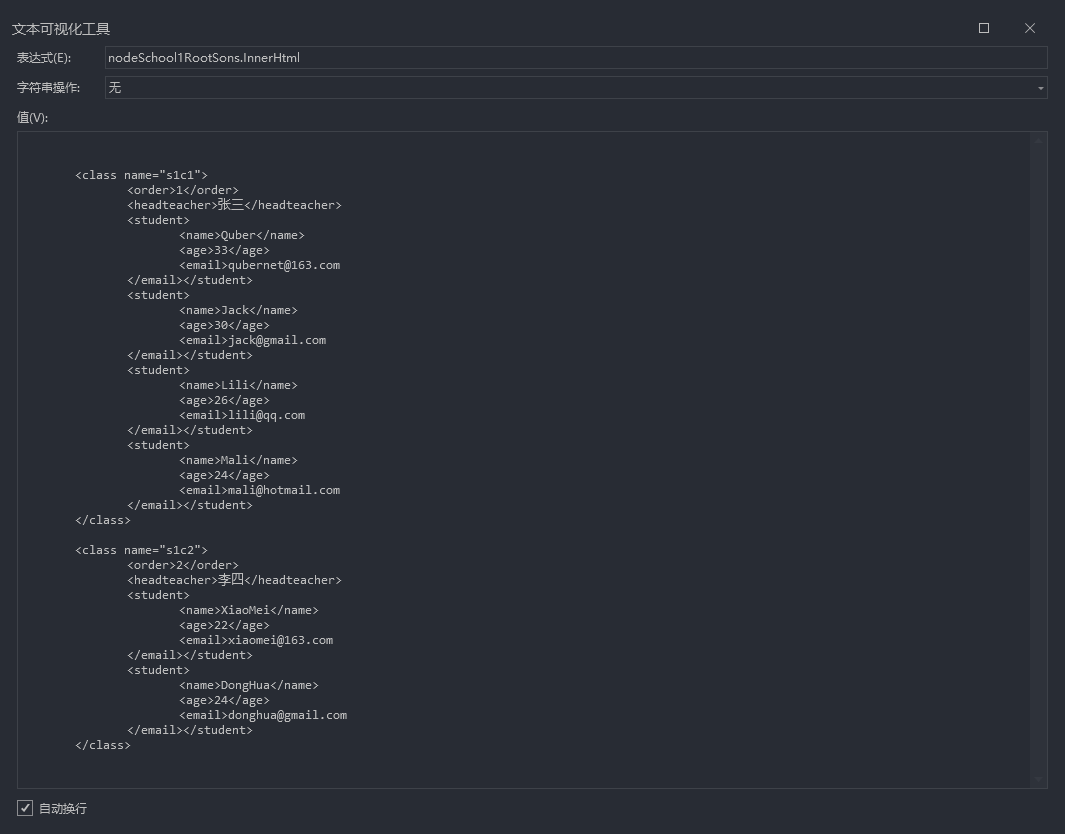
提示
上述中的/school1,代表获取根目录或者某个节点下第一层的school1节点。
/school1:获取根节点中的 school1;
school1/class:获取 school1 下的第一层节点中的 class。
2.3、🍎 获取任何位置的 student 节点
//student
//获取任何位置的student节点
var nodeAllStudent = doc.DocumentNode.SelectNodes("//student");
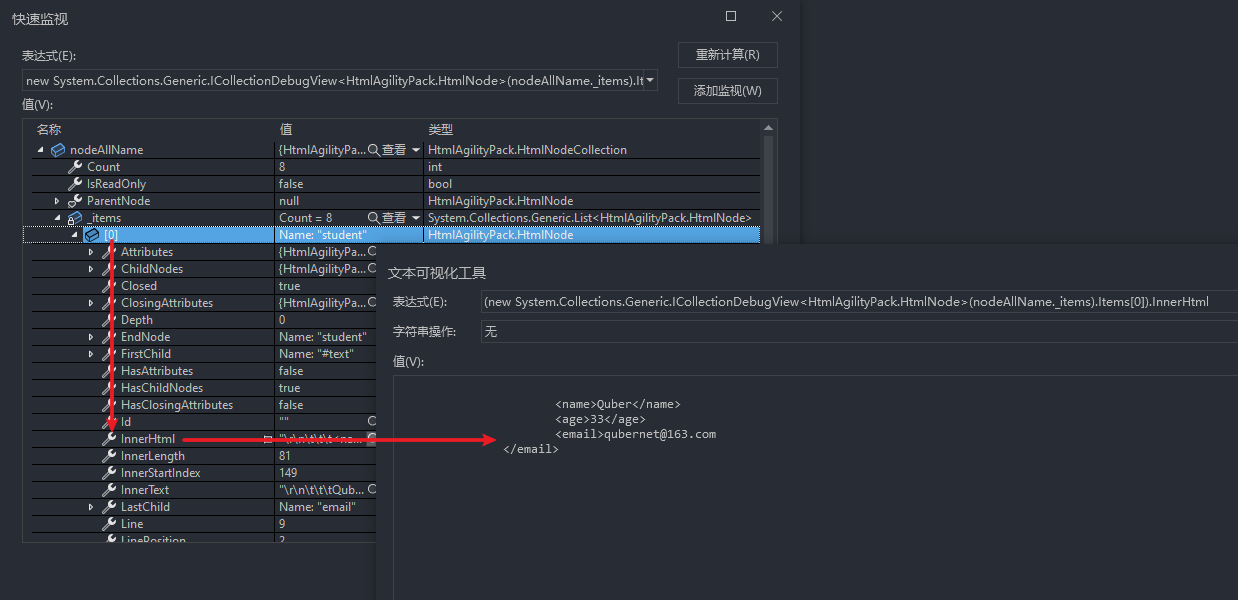
提示
上述中的//student,代表可以从整个 xml 文档中任意一层去获取,没有层级限制。
//student:获取任意层级的 student;
school1//student:获取 school1 下任意层级的 student。
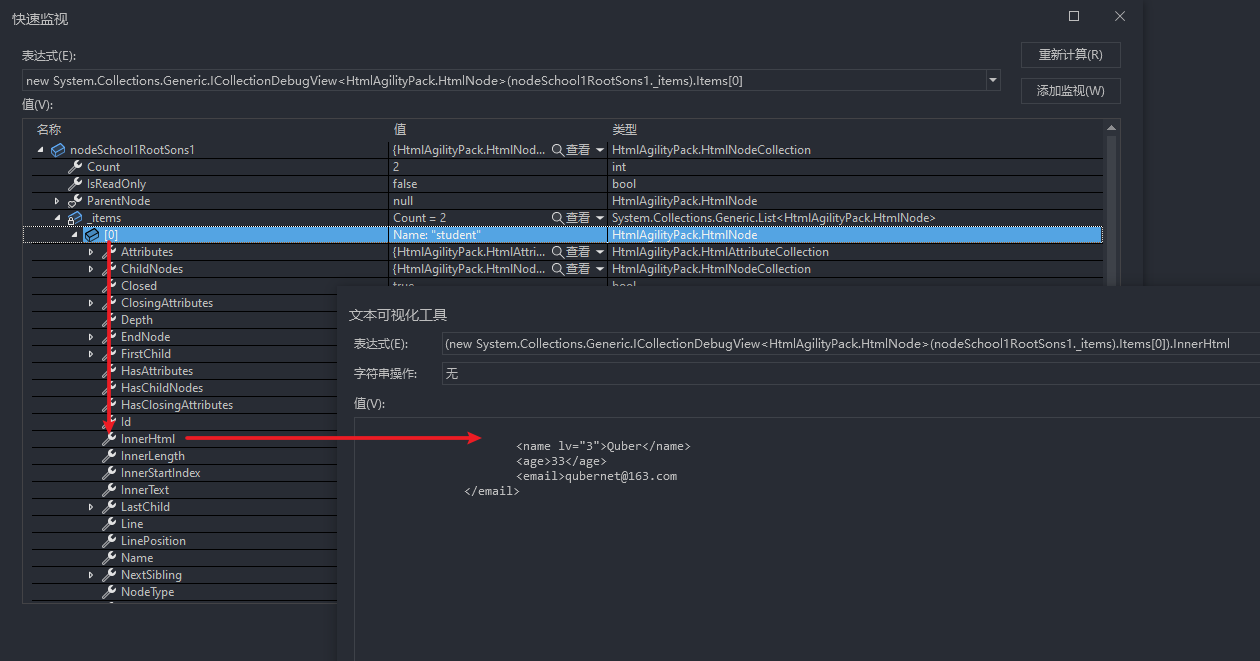
2.4、🍏 获取 student 中包含 lv 属性的所有节点
/school1/class/student/@lv
//获取student中包含lv属性的所有节点
var nodeAllStudentAttr = doc.DocumentNode.SelectNodes("/school1/class/student/@lv");
提示
上述中的/school1/class/student/@lv,代表获取student节点中包含lv属性的所有student节点。
/school1/class/student/@lv:获取 student 中包含 lv 属性的所有节点;
/school1/class/student[@lv='1']:获取 student 中 lv 属性等于 1 的节点。
2.5、🍐 常用语法实例集合
//获取根节点school1及其所有子节点
/school1
//获取school1下的第二个class
/school1/class[2]
//获取school1下最后一个class
/school1/class[last()]
//获取school1下倒数第二个class
/school1/class[last()-1]
//获取school1下前两个class
/school1/class[position()<3]
//获取student中包含lv属性的所有节点
/school1/class/student/@lv
//获取student中lv属性等于1的节点
/school1/class/student[@lv='1']
//获取school1下class中属性desc包含desc2的class节点
/school1/class[contains(@desc,'desc2')]
//获取school1下第一个class节点的父节点,其实就是school1节点(此处就是为了演示..符号的作用,代表父节点的选取)
var nodeSchool1Class1Parent = doc.DocumentNode.SelectSingleNode("/school1/class[1]/..");
//获取school1下的所有class,下面2行语法等同,主要是为了演示符号.的用法
/school1/./class
/school1/class
//获取任何位置的student节点
//student
//获取class下所有student,并且student下的age要大于或等于30
/school1/class/student[age>=30]
//获取student下所有name,并且student下的age要大于或等于30
/school1/class/student[age>=30]/name
//获取student下所有name和age
/school1/class/student/name | /school1/class/student/age
//获取所有节点
//*
//获取所有带属性的class
/school1/class[@*]
3、🍑 实战
下面我们就以获取开源中国的最新资讯和51CTO的开发文章为例进行解析,用到的解析语言为 .Net,解析库为HtmlAgilityPack(官网地址:https://html-agility-pack.net/)。
3.1、🍓 开源中国的最新资讯
通过观察,我们发现开源中国的最新资讯获取直接通过 WebApi 即可获取到文章的 Html 内容,如下图所示:
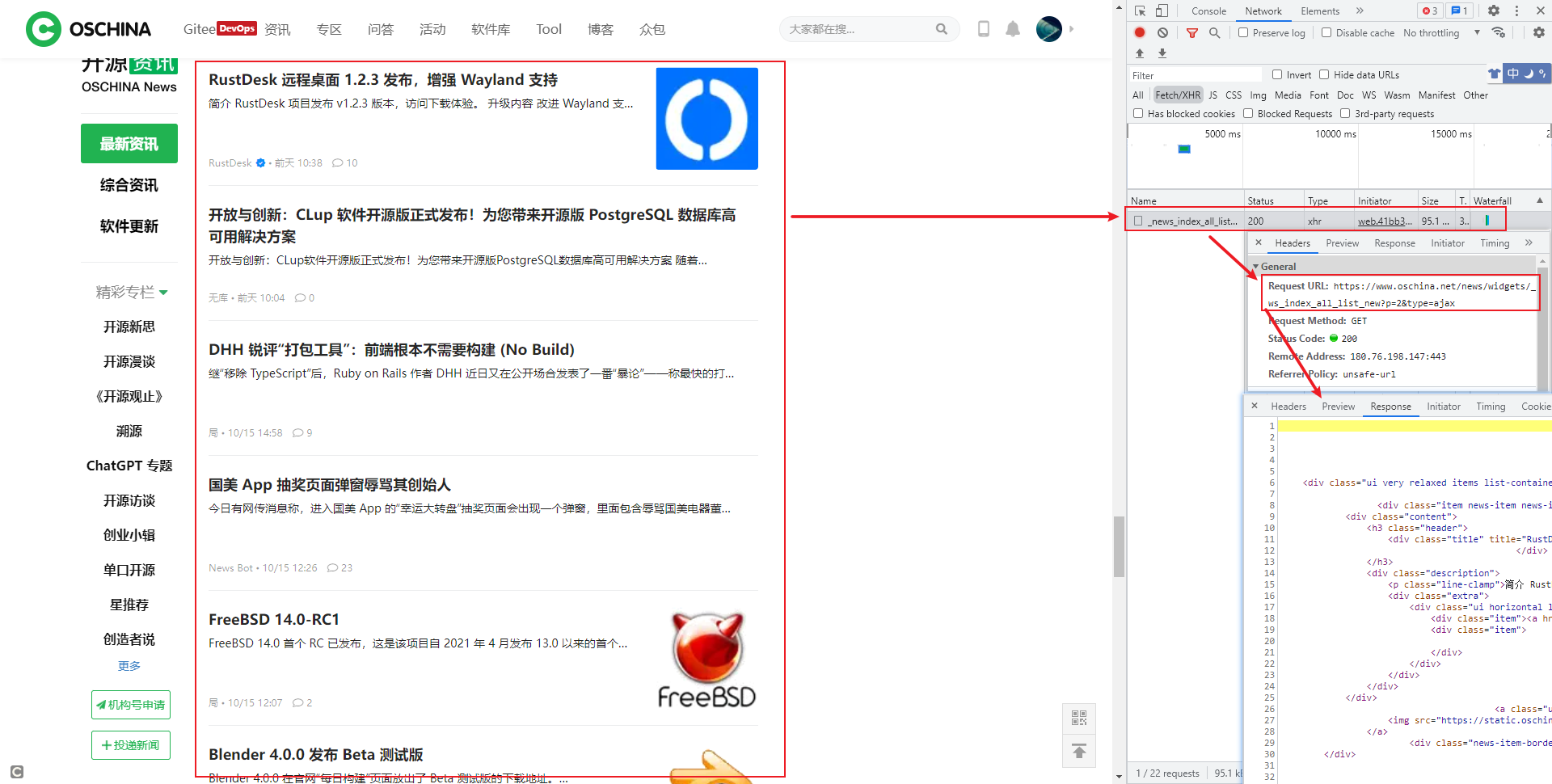
因此,我们可直接使用https://www.oschina.net/news/widgets/_news_index_all_list_new?p=1&type=ajax地址就可以获取到需要解析的 Html 内容,通过该地址我们获取到的 Html 内容如下所示:
Html 内容
<div class="ui very relaxed items list-container news-list-container">
<div class="item news-item news-item-hover" data-url="https://www.oschina.net/news/261905/rustdesk-1-2-3">
<div class="content">
<h3 class="header">
<div class="title" title="RustDesk 远程桌面 1.2.3 发布,增强 Wayland 支持">RustDesk 远程桌面 1.2.3 发布,增强 Wayland 支持
</div>
</h3>
<div class="description">
<p class="line-clamp">简介 RustDesk 项目发布 v1.2.3 版本,访问下载体验。 升级内容 改进 Wayland 支持,光标/剪贴板/多显示器等,但高度依赖 Xwayland,在 GNOME 上运行良好,在 KDE 上兼容性较差。 我们将继续...</p>
<div class="extra">
<div class="ui horizontal list extraOptionList">
<div class="item"><a href="https://my.oschina.net/u/5051711" target="_blank">RustDesk</a><span class="org-label org-label--simple primary" data-tooltip="认证官方账号"><i class="oicon oicon-org"></i></span> <span class="dot">·</span> 前天 10:38 </div>
<div class="item">
<a class="news-comment" data-url="https://www.oschina.net/news/261905/rustdesk-1-2-3#comments"><i class="comment outline icon"></i> 10</a>
</div>
</div>
</div>
</div>
</div>
<a class="ui small image" href="https://www.oschina.net/news/261905/rustdesk-1-2-3" target="_blank">
<img src="https://static.oschina.net/new-osc/img/page/news/loadf0da82b3.png" data-src="https://static.oschina.net/uploads/logo/rustdesk_MBFrJ.png" data-img-render>
</a>
<div class="news-item-border" data-url="https://www.oschina.net/news/261905/rustdesk-1-2-3#comments"></div>
</div>
<div class="item news-item news-comment-item">
<div class="news-comment-dialog hide" data-url="https://www.oschina.net/news/261905/rustdesk-1-2-3#comments">
<div class="dialog-inner">
<div class="title">精彩评论</div>
<div class="content">
<a class="user-avatar" href="https://my.oschina.net/phper08" target="_blank">
<div class="osc-avatar small-portrait _40x40" title="phper08" data-user-id="920476">
<span class="text-portrait" style="background: #8e44ad">p</span>
</div>
</a>
<div class="detail">
<div class="name">
<a class="author" href="https://my.oschina.net/phper08" target="_blank">phper08</a> <span class="time">2023-10-17 09:00</span>
</div>
<div class="des" data-emoji-render>
<div class='detail'>自建服务器要连好几次才能连得上,是什么原因,企鹅的云</div>
</div>
<div class="options">
<span class="btn btn-like" data-toggle-like data-comment-id="296298730">
<i class="oicon oicon-thumb-up"></i>
<span data-comment-like-count data-comment-id="296298730">0</span>赞
</span>
<span class="btn btn-ban ban" ban-report data-id="296298730" data-obj-type="16" data-url="https://www.oschina.net/news/261905/rustdesk-1-2-3#rpl_296298730"><i class="ban icon"></i>举报</span>
</div>
</div>
</div>
<div class="footer">
<a class="more" href="https://www.oschina.net/comment/news/261905" target="_blank">
查看更多评论 <img class="goto" src="https://static.oschina.net/new-osc/img/page/news/icon-goto.png"/></a></h3>
</a>
</div>
</div>
<div class="dialog-border"></div>
</div>
</div>
</div>
<div class="page-load-status">
<p class="infinite-scroll-request">
<i class="ui active small inline loader"></i>
</p>
<p class="infinite-scroll-last">没有更多内容</p>
<p class="infinite-scroll-error">加载失败,请刷新页面</p>
</div>
<a class="ui fluid button load-more-button" style="display: none">加载更多</a>
<p class="pagination">
<a class="all-pagination pagination__next" style="display: none" href="/news/widgets/_news_index_all_list_new?p=4&type=ajax">下一页</a>
</p>
<!-- Generated by oschina (init:1[ms],page:81[ms],ip:222.212.89.20) //-->
说明:以上 Html 内容只展示了部分内容,原始 Html 内容字符太多就没展示完了。
通过上述的 Html 内容,我们可以清晰的看到内容的标题、描述、地址、图片等内容,因此,我们就可以通过.Net 的HtmlAgilityPack组件对其进行解析,代码如下所示:
using HtmlAgilityPack;
namespace Quber.HtmlAgilityPack
{
public class DemoByOsChina
{
public void Test()
{
//文章获取地址
var url = "https://www.oschina.net/news/widgets/_news_index_all_list_new?p=1&type=ajax";
//初始化HtmlWeb对象
var web = new HtmlWeb();
var doc = web.Load(url);
//获取内容列表的根容器(根据div中的class包含news-list-container)
var singleNode = doc.DocumentNode.SelectSingleNode("/div[contains(@class,'news-list-container')]");
//获取跟节点下的所有数据节点
//获取内容列表下的所有文章容器(此处使用contains语法来查找,即:查找div的class属性包含news-item-hover的所有节点)
var allNextNodes = singleNode.SelectNodes("div[contains(@class,'news-item-hover')]");
//文章序号
var serNo = 1;
//循环获取并解析节点
foreach (var item in allNextNodes)
{
//图片和内容节点
HtmlNode imageNode = item.SelectSingleNode("a[contains(@class,'image')]"),
contentNode = item.SelectSingleNode("div[@class='content']");
//图片地址
var imgPath = string.Empty;
if (imageNode != null)
{
imgPath = imageNode
.SelectSingleNode("img")
.GetAttributeValue("data-src", "");
}
//获取标题、描述、文章详细地址、时间、作者和评论数量
string contentTitle = string.Empty,
contentDesc = string.Empty,
contentUrl = item.GetAttributeValue("data-url", ""),
contentTime = string.Empty,
contentAuthor = string.Empty,
contentComment = string.Empty;
if (contentNode != null)
{
contentTitle = contentNode
.SelectSingleNode("h3/div[@class='title']")
.InnerText.Replace("\n", "");
contentDesc = contentNode
.SelectSingleNode("div[@class='description']/p[@class='line-clamp']")
.InnerText;
contentAuthor = contentNode
.SelectSingleNode("div[@class='description']/div[@class='extra']/div[contains(@class,'extraOptionList')]/div[1]/a[1]")
.InnerText;
contentTime = contentNode
.SelectSingleNode("div[@class='description']/div[@class='extra']/div[contains(@class,'extraOptionList')]/div[1]")
.InnerText
.Replace($"{contentAuthor} ·", "")
.Trim();
contentComment = contentNode
.SelectSingleNode("div[@class='description']/div[@class='extra']/div[contains(@class,'extraOptionList')]/div[2]/a[1]")
.InnerText
.Trim();
}
//输出显示
Console.WriteLine(@$"
序号:{serNo}
标题:{contentTitle}
描述:{contentDesc}
图片:{imgPath}
地址:{contentUrl}
时间:{contentTime}
作者:{contentAuthor}
评论:{contentComment}
");
serNo++;
}
}
}
}
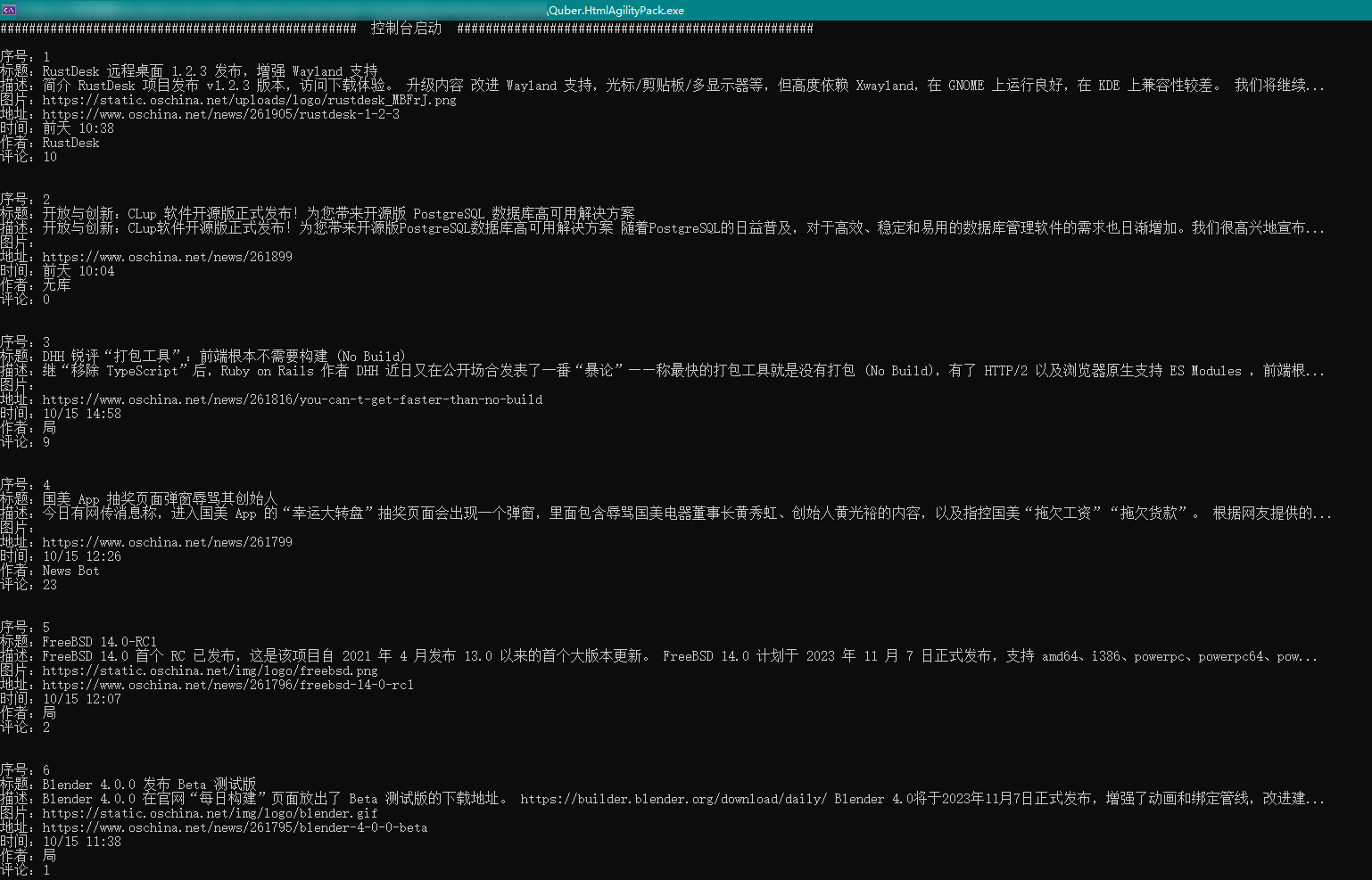
最终解析出来的数据如下图所示:
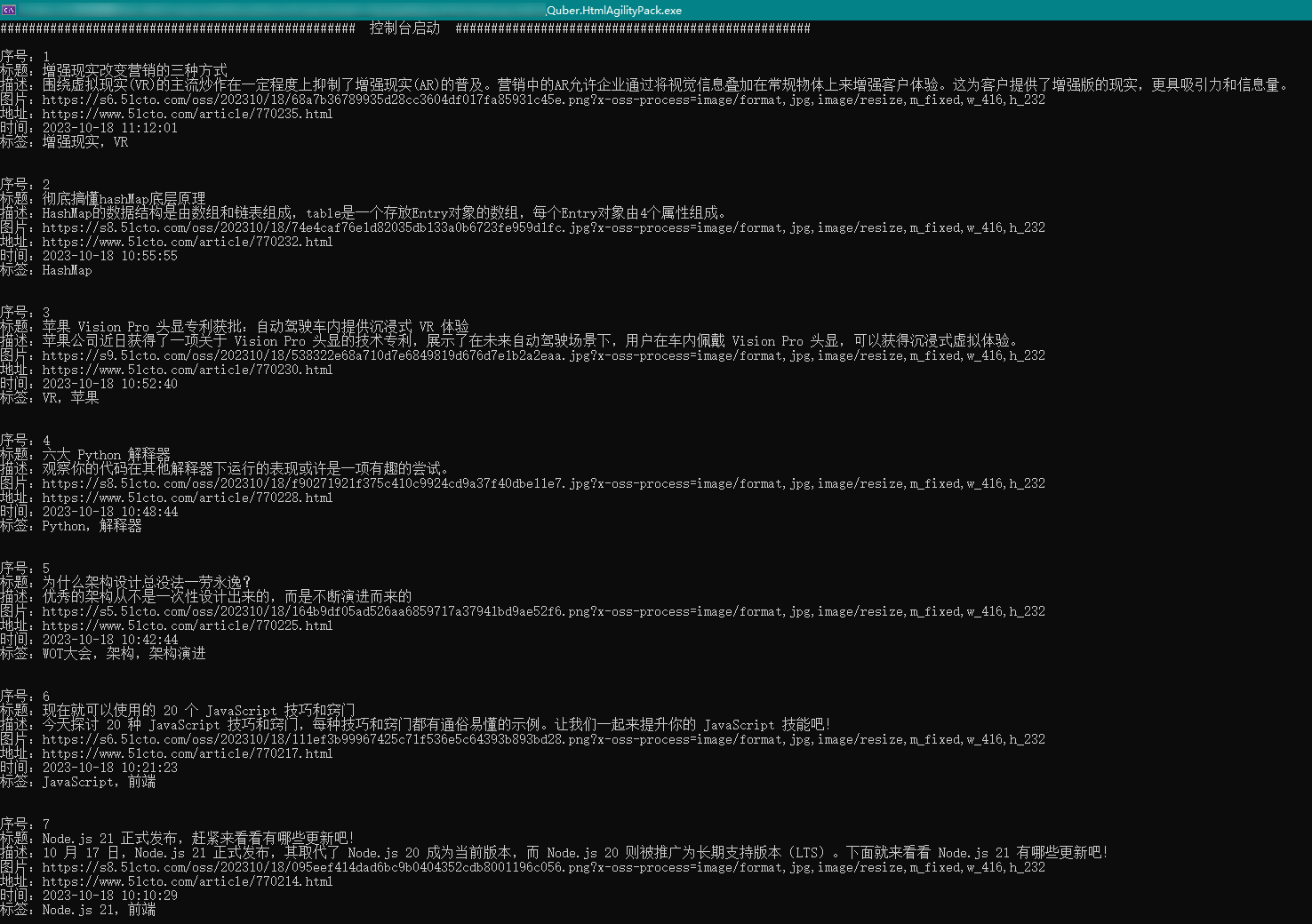
3.2、🍅51CTO 的开发
通过观察,我们发现 51CTO 的开发获取直接通过 Web 地址即可获取到文章的 Html 内容,如下图所示:
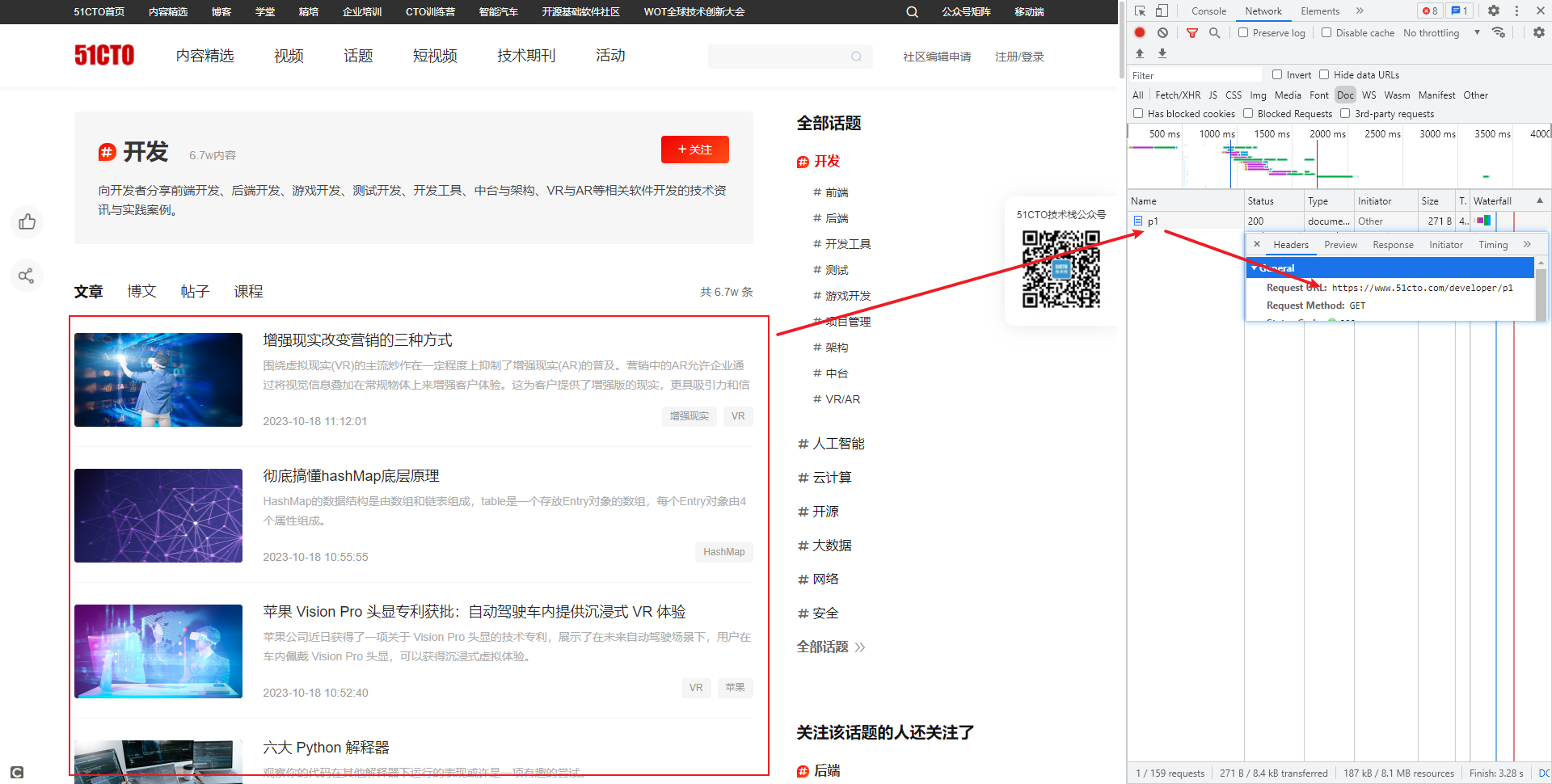
因此,我们可直接使用https://www.51cto.com/developer/p1地址就可以获取到需要解析的 Html 内容,通过该地址我们获取到的 Html 内容如下所示:
Html 内容
<div class="components-topic-list-content topic-list-content">
<div class="article-articleitem article-ir articleItem">
<div class="article-irl article-irl_border">
<div class="article-irl-img usehover">
<a
href="https://www.51cto.com/article/770235.html"
target="_blank"
><img
src="https://s6.51cto.com/oss/202310/18/68a7b36789935d28cc3604df017fa85931c45e.png?x-oss-process=image/format,jpg,image/resize,m_fixed,w_416,h_232"
alt=""
/></a>
</div>
<div class="article-irl-c split-left-l">
<div class="title-box">
<div class="article-irl-ct">
<a
href="https://www.51cto.com/article/770235.html"
target="_blank"
class="usehover article-irl-ct_title"
>增强现实改变营销的三种方式</a
>
<!---->
<!---->
</div>
<a
href="https://www.51cto.com/article/770235.html"
target="_blank"
class="split-top-m usehover pc-three-line article-abstract"
>围绕虚拟现实(VR)的主流炒作在一定程度上抑制了增强现实(AR)的普及。营销中的AR允许企业通过将视觉信息叠加在常规物体上来增强客户体验。这为客户提供了增强版的现实,更具吸引力和信息量。</a
>
</div>
<div class="article-irl-cb">
<p class="article-irl-cb_time">2023-10-18 11:12:01</p>
<div class="article-irl-cb_sign">
<a
target="_blank"
href="https://so.51cto.com/?keywords=%E5%A2%9E%E5%BC%BA%E7%8E%B0%E5%AE%9E"
class="split-left-m usehover"
>增强现实</a
><a
target="_blank"
href="https://so.51cto.com/?keywords=VR"
class="split-left-m usehover"
>VR</a
>
</div>
</div>
</div>
</div>
<!---->
</div>
<!---->
<div class="article-articleitem article-ir articleItem">
<div class="article-irl article-irl_border">
<div class="article-irl-img usehover">
<a
href="https://www.51cto.com/article/770232.html"
target="_blank"
><img
src="https://s8.51cto.com/oss/202310/18/74e4caf76e1d82035db133a0b6723fe959d1fc.jpg?x-oss-process=image/format,jpg,image/resize,m_fixed,w_416,h_232"
alt=""
/></a>
</div>
<div class="article-irl-c split-left-l">
<div class="title-box">
<div class="article-irl-ct">
<a
href="https://www.51cto.com/article/770232.html"
target="_blank"
class="usehover article-irl-ct_title"
>彻底搞懂hashMap底层原理</a
>
<!---->
<!---->
</div>
<a
href="https://www.51cto.com/article/770232.html"
target="_blank"
class="split-top-m usehover pc-three-line article-abstract"
>HashMap的数据结构是由数组和链表组成,table是一个存放Entry对象的数组,每个Entry对象由4个属性组成。</a
>
</div>
<div class="article-irl-cb">
<p class="article-irl-cb_time">2023-10-18 10:55:55</p>
<div class="article-irl-cb_sign">
<a
target="_blank"
href="https://so.51cto.com/?keywords=HashMap"
class="split-left-m usehover"
>HashMap</a
>
</div>
</div>
</div>
</div>
<!---->
</div>
</div>
说明:以上 Html 内容只展示了部分内容,原始 Html 内容字符太多就没展示完了。
通过上述的 Html 内容,我们可以清晰的看到内容的标题、描述、地址、图片等内容,因此,我们就可以通过.Net 的HtmlAgilityPack组件对其进行解析,代码如下所示:
using HtmlAgilityPack;
namespace Quber.HtmlAgilityPack
{
public class DemoBy51CtoDev
{
public void Test()
{
//文章获取地址
var url = "https://www.51cto.com/developer/p1";
//初始化HtmlWeb对象
var web = new HtmlWeb();
var doc = web.Load(url);
//获取内容列表的根容器(<div class="components-topic-list-content topic-list-content">)
var singleNode = doc.DocumentNode.SelectSingleNode("//div[@class='components-topic-list-content topic-list-content']");
//获取内容列表下的所有文章容器(此处使用contains语法来查找,即:查找div的class属性包含article-articleitem的所有节点)
var allNextNodes = singleNode.SelectNodes("div[contains(@class,'article-articleitem')]");
//文章序号
var serNo = 1;
//循环获取并解析节点
foreach (var item in allNextNodes)
{
//图片和内容节点
HtmlNode imageNode = item.SelectSingleNode("div[contains(@class,'article-irl')]/div[contains(@class,'article-irl-img')]"),
contentNode = item.SelectSingleNode("div[contains(@class,'article-irl')]/div[contains(@class,'article-irl-c')]");
//图片地址
var imgPath = string.Empty;
if (imageNode != null)
{
imgPath = imageNode
.SelectSingleNode("a/img")
.GetAttributeValue("src", "");
}
//获取标题、描述、文章详细地址、时间和标签
string contentTitle = string.Empty,
contentDesc = string.Empty,
contentUrl = string.Empty,
contentTime = string.Empty;
var contentTags = new List<string>();
if (contentNode != null)
{
//获取到标题所在的a标签元素
var titleLinkNode = contentNode.SelectSingleNode("div[@class='title-box']/div[@class='article-irl-ct']/a");
//获取标题和文章详细地址
contentTitle = titleLinkNode.InnerText;
contentUrl = titleLinkNode.GetAttributeValue("href", "");
//获取描述
contentDesc = contentNode
.SelectSingleNode("div[@class='title-box']/a")
.InnerText;
//获取时间
contentTime = contentNode
.SelectSingleNode("div[@class='article-irl-cb']/p")
.InnerText;
//获取标签节点集合
var tagNodes = contentNode.SelectNodes("div[@class='article-irl-cb']/div/a");
//获取标签
foreach (var tag in tagNodes)
{
contentTags.Add(tag.InnerText);
}
}
//输出显示
Console.WriteLine(@$"
序号:{serNo}
标题:{contentTitle}
描述:{contentDesc}
图片:{imgPath}
地址:{contentUrl}
时间:{contentTime}
标签:{string.Join(',', contentTags)}
");
serNo++;
}
}
}
}
最终解析出来的数据如下图所示: