基本使用
PostgreSQL 说明
本章,我们主要从数据库权限、数据库管理、表管理和常用 SQL 查询这几个方面进行介绍!
1、🍕 数据库权限
在 PostgreSQL 安装完成后,会自动创建一个名称为 postgres 的用户和数据库。
1、组角色
一个组角色可以看作一组数据库用户。组角色可以拥有数据库对象(比如表),并可以把这些对象上的权限赋予其他角色,以控制谁拥有访问哪些对象的权限。
SELECT * FROM pg_roles;
--注意:在创建角色有,会在用户表中同步创建同名的用户
CREATE ROLE testrole;
ALTER ROLE testrole RENAME TO testrole1;
--注意:在删除角色的时候,会将创建的同名用户一起删除
DROP ROLE testrole;
注意
在创建角色有,会在用户表中同步创建同名的用户;
在删除角色的时候,会将创建的同名用户一起删除。
2、角色权限
角色权限包含有登录、超级用户、创建数据库、创建角色和口令等。
CREATE ROLE testrole LOGIN;
--superuser超级用户拥有对数据库操作的最高权限,可以完成对数据库的所有权限进行检查
--注意:只有超级用户才能有权限创建超级用户
CREATE ROLE testrole SUPERUSER;
CREATE ROLE testrole CREATEDB;
CREATE ROLE testrole CREATEROLE;
--在客户认证方法要求与数据库建立连接时,需要口令权限。常见的认证方法包括:password、md5、crypt
CREATE ROLE testrole PASSWORD '123456';
注意
superuser 超级用户拥有对数据库操作的最高权限,可以完成对数据库的所有权限进行检查;
只有超级用户才能有权限创建超级用户。
3、用户管理
我们可使用CREATE USER或CREATE ROLE命令来创建用户
SELECT * FROM pg_user;
--密码为123456,拥有创建数据库和创建角色的权限
CREATE USER testuser PASSWORD '123456' CREATEDB CREATEROLE;
ALTER USER testuser RENAME TO testuser1;
DROP USER testuser;
ALTER USER testuser PASSWORD '666666';
4、组角色和用户权限管理
ALTER ROLE testrole CREATEDB CREATEROLE;
ALTER USER testuser CREATEDB CREATEROLE;
ALTER ROLE testrole NOCREATEDB NOCREATEROLE;
ALTER USER testuser NOCREATEDB NOCREATEROLE;
5、数据库权限管理
ALTER DATABASE testdb OWNER TO testuser;
--注意:必须给用户testuser设置schema的使用权,否则会报错
GRANT USAGE ON SCHEMA PUBLIC TO testuser;
--将数据表testtb的UPDATE权限授权给用户testuser
GRANT UPDATE ON testtb TO testuser;
REVOKE ALL ON testdb FROM testuser;
REVOKE ALL ON SCHEMA PUBLIC FROM testuser;
权限
其中的权限包含有:SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE 、USAGE 和 ALL 等。
GRANT privilege
ON object
TO { PUBLIC | GROUP group | username };
说明:
privilege:权限类型,值可以是 SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE 、USAGE 和 ALL 等;
object:要授予访问权限的对象名称,可能的对象有:table、view、sequence 等;
PUBLIC:表示所有用户;
GROUP group:为用户组授予权限;
username:要授予权限的用户名,PUBLIC是代表所有用户的简短形式。
注意
使用 schema 的时候:
需要用 postgres 授权指定的 schema 的使用(USAGE)权限给特定用户;
然后授权 postgres 需要的权限到特定用户。
这两个缺一不可。
2、🍔 数据库管理
2.1、🍿 数据库创建
如下所示为创建名称为testdb的数据库 SQL 语句:
CREATE DATABASE testdb
WITH
OWNER = testuser
ENCODING = 'UTF8'
--TEMPLATE = postgres
--ALLOW_CONNECTIONS = FALSE
LC_COLLATE = 'Chinese (Simplified)_China.936'
LC_CTYPE = 'Chinese (Simplified)_China.936'
TABLESPACE = pg_default
CONNECTION LIMIT = -1
IS_TEMPLATE = False;
COMMENT ON DATABASE testdb
IS '测试数据库';
说明:
testdb:要创建的数据库的名称;
OWNER:要创建的数据库所属的用户。如果没有指定,则默认属于执行该命令的用户;
ENCODING:用于描述新数据库的字符集编码,默认为 UTF8;
TEMPLATE:要创建的数据库所用的模版库,默认的模版库是 template1;
ALLOW_CONNECTIONS:是否可以连接该数据库,默认设置为 true。如果设置为 false,则任何用户都不能连接该数据库;
LC_COLLATE:要创建的数据库所使用的 collation 顺序。这会影响在 ORDER_BY 语法中字符串类型列的顺序,也会影响 text 类型列的索引顺序。如果没有指定,则默认使用其模版库的 collation 顺序;
LC_CTYPE:要创建的数据库所使用的字符分类。如大小写和数字。如果没有指定,则默认使用其模版库的字符分类;
TABLESPACE:表空间,用于定义新数据库的表空间名称,默认为模板数据库的表空间;
CONNECTION:该参数用于定义新数据库的最大并行连接数,默认为-1(无限制);
IS_TEMPLATE:是否是模版库,默认设置为 false。如果设置为 true,则任何具有创建数据库权限的用户均可以用其复制新的数据库;如果设置为 false,则只有超级用户和该数据库的用户可以其复制新的数据库;
COMMENT ON DATABASE testdb IS '测试数据库':修改数据库 testdb 的说明信息为“测试数据库”。
SELECT * FROM pg_database;
2.2、🥓 数据库修改
修改数据库名称:
ALTER DATABASE testdb RENAME TO testdb1;
修改数据库最大连接数:
ALTER DATABASE testdb CONNECTION LIMIT 100;
提示
如果要修改数据库的其他配置,可参考创建数据库中的相关配置进行修改。
2.3、🧇 数据库删除
删除数据库:
--注意:如果数据库testdb不存在,则在执行如下语句的时候会报错
DROP DATABASE testdb;
删除数据库:
--注意:如果数据库testdb不存在,则在执行如下语句的时候不会报错
DROP DATABASE IF EXISTS testdb;
注意
在删除某数据库时,如果数据库不存在,使用DROP DATABASE testdb;会报错,使用DROP DATABASE IF EXISTS testdb就不会报错了。
3、🍟 表管理
3.1、🥞 表创建
在创建数据表前,我们先创建一个名称为user_info的复合数据类型,以便于在创建数据表时某字段使用:
创建复合数据类型 user_info
--创建复合类型(对象)
CREATE TYPE user_info AS(
UserName varchar(50),
UserAge int4
)
如下所示为创建名称为testtb的表 SQL 语句:
CREATE TABLE "testtb" (
"Id" int8 NOT NULL,
"Name" varchar(50) NOT NULL,
"Type" varchar(20) NOT NULL,
"Age" int4 NOT NULL,
"RoleIds" int8[] NOT NULL,
"Note" varchar(200),
"IsEnable" bool NOT NULL,
"CreateTime" timestamp NOT NULL,
"CreateDate" date,
"Price" money,
"Guid" uuid,
"Json" json,
"JsonB" jsonb,
"Test" text,
"UserInfo" user_info, --该字段为复合数据类型
PRIMARY KEY ("Id")
);
COMMENT ON COLUMN "testtb"."Id" IS '主键Id';
COMMENT ON COLUMN "testtb"."Name" IS '用户姓名';
COMMENT ON COLUMN "testtb"."Type" IS '用户性别';
COMMENT ON COLUMN "testtb"."Age" IS '用户年龄';
COMMENT ON COLUMN "testtb"."RoleIds" IS '所属角色Id集合';
COMMENT ON COLUMN "testtb"."Note" IS '备注';
COMMENT ON COLUMN "testtb"."IsEnable" IS '是否启用';
COMMENT ON COLUMN "testtb"."CreateTime" IS '创建时间';
COMMENT ON COLUMN "testtb"."CreateDate" IS '创建日期';
COMMENT ON COLUMN "testtb"."Price" IS '价格';
COMMENT ON COLUMN "testtb"."Guid" IS 'Guid';
COMMENT ON COLUMN "testtb"."Json" IS 'Json';
COMMENT ON COLUMN "testtb"."JsonB" IS 'JsonB';
COMMENT ON COLUMN "testtb"."Test" IS 'Text';
COMMENT ON COLUMN "testtb"."UserInfo" IS '用户信息,数据类型为自定义符合类型user_info';
COMMENT ON TABLE "testtb" IS '测试表';
查询所有表:
SELECT * FROM pg_tables;
SELECT * FROM pg_tables WHERE schemaname='public';
3.2、🍞 表修改
修改表名称:
ALTER TABLE testtb RENAME TO testtb1;
修改字段类型:
--注意:因为字段Name是PostgreSQL中的关键字,因此需要加双新号,非关键字可不加
ALTER TABLE testtb ALTER COLUMN "Name" TYPE TEXT;
修改字段名称:
ALTER TABLE testtb RENAME "Name" TO Name1;
增加新字段:
ALTER TABLE testtb ADD COLUMN Name1 VARCHAR(50) NOT NULL DEFAULT '测试内容';
删除字段:
ALTER TABLE testtb DROP Name1;
删除外键:
ALTER TABLE testtb DROP CONSTRAINT fk_name1;
注意
在修改字段类型的时候,如果字段名称为 PostgreSQL 中的关键字(如
Name),需要使用双引号将 Name 包含起来,否则在执行 Sql 的时候会报错;在数据表有数据的时候修改某字段的数据类型,需要特别注意。例如字段 A 中存储了大概有 100 长度的字符内容,这时候将字段 A 的类型修改为**VARCHAR(50)**就会报错;
如果某表已经存在了数据,这时候新增某字段,并且这个字段约束条件为不为空,此时会报错,因此需要注意下。
3.3、🥐 表删除
删除表:
--注意:如果表testtb不存在,则在执行如下语句的时候会报错
DROP TABLE testtb;
删除表:
--注意:如果表testtb不存在,则在执行如下语句的时候不会报错
DROP TABLE IF EXISTS testtb;
注意
在删除某表时,如果表不存在,使用DROP TABLE testtb;会报错,使用DROP TABLE IF EXISTS testtb就不会报错了。
4、🌭 常用 SQL 查询
针对常用 SQL 查询,我们以创建数据表 testtb 为例来演示操作该表数据的各种操作。
4.1、🧀 添加数据 SQL
在上面的3.1、表创建章节中,我们使用 SQL 语句在数据库 testdb 创建了数据表testtb,如下所示:
表创建 SQL
CREATE TABLE "testtb" (
"Id" int8 NOT NULL,
"Name" varchar(50) NOT NULL,
"Type" varchar(20) NOT NULL,
"Age" int4 NOT NULL,
"RoleIds" int8[] NOT NULL,
"Note" varchar(200),
"IsEnable" bool NOT NULL,
"CreateTime" timestamp NOT NULL,
"CreateDate" date,
"Price" money,
"Guid" uuid,
"Json" json,
"JsonB" jsonb,
"Test" text,
"UserInfo" user_info, --该字段为复合数据类型
PRIMARY KEY ("Id")
);
COMMENT ON COLUMN "testtb"."Id" IS '主键Id';
COMMENT ON COLUMN "testtb"."Name" IS '用户姓名';
COMMENT ON COLUMN "testtb"."Type" IS '用户性别';
COMMENT ON COLUMN "testtb"."Age" IS '用户年龄';
COMMENT ON COLUMN "testtb"."RoleIds" IS '所属角色Id集合';
COMMENT ON COLUMN "testtb"."Note" IS '备注';
COMMENT ON COLUMN "testtb"."IsEnable" IS '是否启用';
COMMENT ON COLUMN "testtb"."CreateTime" IS '创建时间';
COMMENT ON COLUMN "testtb"."CreateDate" IS '创建日期';
COMMENT ON COLUMN "testtb"."Price" IS '价格';
COMMENT ON COLUMN "testtb"."Guid" IS 'Guid';
COMMENT ON COLUMN "testtb"."Json" IS 'Json';
COMMENT ON COLUMN "testtb"."JsonB" IS 'JsonB';
COMMENT ON COLUMN "testtb"."Test" IS 'Text';
COMMENT ON COLUMN "testtb"."UserInfo" IS '用户信息,数据类型为自定义符合类型user_info';
COMMENT ON TABLE "testtb" IS '测试表';
接下来我们向该表中添加 4 条数据:
INSERT INTO testtb
VALUES(289480312365125,'张三','男',22,ARRAY[1,2,3],'备注1',true,NOW(),CURRENT_DATE,100.56,gen_random_uuid(),'{"Name":"张三","Detail":{"Email":"1@qq.com","Mobile":"13551111111","Count":100,"Items":[1,2]}}','{"Name":"张三","Detail":{"Email":"1@qq.com","Mobile":"13551111111","Count":100,"Items":[1,2]}}','text1',
ROW('Quber',32));
INSERT INTO testtb
VALUES(289480420171845,'李四','女',32,ARRAY[4,5,6],'备注2',true,NOW(),CURRENT_DATE,982.66,gen_random_uuid(),'{"Name":"李四","Detail":{"Email":"2@qq.com","Mobile":"13551111112","Count":200,"Items":[3,4]}}','{"Name":"李四","Detail":{"Email":"2@qq.com","Mobile":"13551111112","Count":200,"Items":[3,4]}}','text2',
ROW('Jack',29));
INSERT INTO testtb
VALUES(289480483520581,'王五','男',28,ARRAY[7,8,9],'备注3',true,NOW(),CURRENT_DATE,186.89,gen_random_uuid(),'{"Name":"王五","Detail":{"Email":"3@qq.com","Mobile":"13551111111","Count":150,"Items":[6,7,8,1]}}','{"Name":"王五","Detail":{"Email":"3@qq.com","Mobile":"13551111111","Count":150,"Items":[6,7,8,1]}}','text3',
ROW('Lili',18));
INSERT INTO testtb
VALUES(289480581697605,'赵六','女',18,ARRAY[10,11,12,15],'备注4',true,NOW(),CURRENT_DATE,222.88,gen_random_uuid(),'{"Name":"赵六","Detail":{"Email":"4@qq.com","Mobile":"13551111112","Count":266,"Items":[5,6,7]}}','{"Name":"赵六","Detail":{"Email":"4@qq.com","Mobile":"13551111112","Count":266,"Items":[5,6,7]}}','text4',
ROW('Maya',24));
数据表 testtb 的所有数据:

数据表 testtb 指定字段的所有数据:

说明
RoleIds 字段:该字段的数据类型为
int8[],即 bigint 的数组类型,因此在写 SQL 添加语句的时候,需要用到 PostgreSQL 中的 ARRAY 函数作为转换,如:ARRAY[1,2,3];IsEnable 字段:该字段的数据类型为
bool,所以对应的值直接传true或false即可;CreateTime 字段:该字段的数据类型为
timestamp,所以我们可以直接使用 PostgreSQL 自带的函数NOW()即可;CreateDate 字段:该字段的数据类型为
date,所以我们可以直接使用 PostgreSQL 自带的属性CURRENT_DATE即可;Guid 字段:该字段的数据类型为
uuid,所以我们可以直接使用 PostgreSQL 自带的函数gen_random_uuid()即可;Json 字段:该字段的数据类型为
json,我们直接传字符串的 JSON 对象即可;JsonB 字段:该字段的数据类型为
jsonb,我们直接传字符串的 JSON 对象即可;UserInfo 字段:该字段为的数据类型为
复合数据类型,因此我们在创建表前需要先使用TYPE去创建对应的自定义复合数据类型,如上面的表中我们就创建了名称为user_info的复合数据类型,如下所示:--创建复合类型(对象) CREATE TYPE user_info AS( UserName varchar(50), UserAge int4 ) --查询表testtb中复合类型字段UserInfo中所有的UserName,条件为UserInfo中的UserAge字段大于24 SELECT ("UserInfo").UserName 复合类型中的用户姓名 FROM testtb WHERE ("UserInfo").UserAge > 24;
4.2、🥗 对数组字段的操作
将数据表 testtb 中字段 RoleIds 中的第一个查询出来:
SELECT "RoleIds"[1] FROM testtb;如果索引超过了数组的长度,则会返回 null。
注意:
"RoleIds"[1]中的 1 就代表数组中的第一个值,而不是使用 0 作为第一个,即:使用 1 作为获取数组中的第一个值。数组类型操作符:
数组类型操作符
操作符 描述 例子 结果 = 等于 SELECT ARRAY[1.1,2.1,3.1]::int[] = ARRAY[1,2,3] AS 结果; true <> 不等于 SELECT ARRAY[1,2,3] <> ARRAY[1,2,4] AS 结果; true < 小于 SELECT ARRAY[1,2,3] < ARRAY[1,2,4] AS 结果; true > 大于 SELECT ARRAY[1,4,3] > ARRAY[1,2,4] AS 结果; true <= 小于或等于 SELECT ARRAY[1,2,3] <= ARRAY[1,2,3] AS 结果; true >= 大于或等于 SELECT ARRAY[1,4,3] >= ARRAY[1,4,3] AS 结果; true @> 包含 SELECT ARRAY[1,4,3] @> ARRAY[3,1] AS 结果; true <@ 被包含于 SELECT ARRAY[2,7] <@ ARRAY[1,7,4,2,6] AS 结果; true && 重叠(有共同元素) SELECT ARRAY[1,4,3] && ARRAY[2,1] AS 结果; true || 数组与数组连接 SELECT ARRAY[1,2,3] || ARRAY[4,5,6] AS 结果; {1,2,3,4,5,6} || 数组与数组连接 SELECT ARRAY[1,2,3] || ARRAY[[4,5,6],[7,8,9]] AS 结果; {\{1,2,3\},\{4,5,6\},\{7,8,9\}} || 元素与数组连接 SELECT 3 || ARRAY[4,5,6] AS 结果; {3,4,5,6} || 数组与元素连接 SELECT ARRAY[4,5,6] || 7 AS 结果; {4,5,6,7} 函数(内容修改)
函数(内容修改)
这部分函数主要是针对数组类型的返回结果进行处理。
函数 说明 语句 结果 array_append 向数组的末尾添加元素 SELECT array_append(ARRAY[1,2], 3) AS 结果; {1,2,3} array_prepend 向数组的开头添加函数 SELECT array_prepend(1, ARRAY[2,3]) AS 结果; {1,2,3} array_cat 连接两个数组 SELECT array_cat(ARRAY[1,2,3], ARRAY[4,5]) AS 结果; {1,2,3,4,5} array_replace 用新值替换每个等于给定值的数组元素 SELECT array_replace(ARRAY[1,2,5,4], 5, 3) AS 结果; {1,2,3,4} [start:end] [2:4],取出数组中第二个到第四个的值 SELECT (ARRAY[1,2,3,4,5])[2:4] AS 结果; {2,3,4} 函数(信息查询)
函数(信息查询)
这部分函数主要是对数组数据的源数据进行查询。
函数 说明 语句 结果 array_dims 返回数组维数的文本表示 SELECT array_dims(ARRAY[[1,2,3], [4,5,6]]) AS 结果; [1:2][1:3] array_lower 返回数组维数的下界 SELECT array_lower('[0:2]={1,2,3}'::int[], 1) AS 结果; 0 array_upper 返回数组维数的上界 SELECT array_upper(ARRAY[1,8,3,7], 1) AS 结果; 4 array_ndims 返回数组的维数 SELECT array_ndims(ARRAY[[1,2,3], [4,5,6]]) AS 结果; 2 array_length 返回数组维度的长度 SELECT array_length(array[1,2,3], 1) AS 结果; 3 array_position 数组中指定元素出现的位置 SELECT array_position(ARRAY[1,8,3,7], 8) AS 结果; 2 cardinality 返回数组中的总元素数量,或者如果数组是空的则为 0 SELECT cardinality(ARRAY[1,2,3,5]) AS 结果; 4 函数(转换)
函数(转换)
这里面的函数提供了数组和字符串的转换,在实际应用中,这部分的逻辑使用的会比较多。很多时候一些查询中我们数据类型是个字符串,但是符合数组的结构特征,我们希望以数组的特性去操作这个字符串,这里面的函数无疑是必要的。
函数 说明 语句 结果 array_to_string 将数组转换为字符串,使用分隔符和 null 字符串连接数组元素 SELECT array_to_string(ARRAY[1, 2, 3, NULL, 5], ',', 'N') AS 结果; 1,2,3,N,5 string_to_array 使用指定的分隔符和 null 字符串把字符串分裂成数组元素 SELECT string_to_array('A,B,C,D',',') AS 结果; {A,B,C,D} 函数(结果转换)
函数(结果转换)
这部分的函数,会将数组结果进行合并和展开。
函数 说明 语句 结果 array_agg 把多个值合并到一个数组中 SELECT "Type",array_agg("Age" ORDER BY "Age") AS 结果 FROM testtb GROUP BY "Type"; 男 {22,28}
女 {18,32}unnest 扩大一个数组为一组行 SELECT unnest(ARRAY[1,2,3,4]) AS 结果; 1
2
3
4
4.3、🥙 对 JSON 字段的操作
主要针对队数据类型为 JSON 和 JSONB 进行各项操作。
JSON 和 JSONB 目的都是用于存储 JSON 数据,不同点在于:
JSON 类型会存储原始完整的 JSON 格式,包括空格和换行等;
JSONB 类型会存储为二进制格式;
JSON 类型在写入的时候效率高于 JSONB;
JSONB 类型在读取数据的时候效率高于 JSON;
JSONB 支持的操作函数更多。
将数据表 testtb 中的字段 JsonB 中的所有 Name 查询出来:
SELECT "JsonB" ->> 'Name' 姓名 FROM testtb;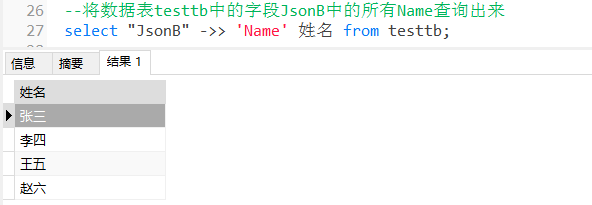
4.3.1 将数据表 testtb 中的字段 JsonB 中的所有 Detail 中的 Email 查询出来:
SELECT "JsonB" -> 'Detail' ->> 'Email' 邮箱 FROM testtb;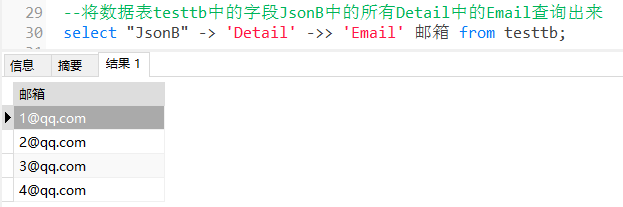
4.3.2 将数据表 testtb 中的字段 JsonB 中的所有 Detail 中的 Items 中的第二个值查询出来:
SELECT "JsonB" -> 'Detail' -> 'Items' ->> 1 结果 FROM testtb;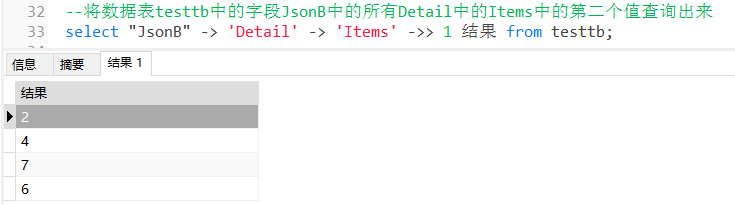
4.3.3 将数据表 testtb 中的字段 JsonB 中的所有 Name 查询出来,在 Where 中使用 JSON 查询:
--查询条件为字段JsonB中的Detail中的Mobile = '13551111111' SELECT "JsonB" ->> 'Name' 姓名 FROM testtb WHERE "JsonB" -> 'Detail' ->> 'Mobile' = '13551111111';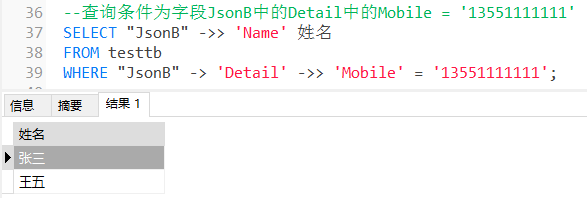
4.3.4-1 --查询条件为字段JsonB中的Detail中的Count >= 200 SELECT "JsonB" ->> 'Name' 姓名 FROM testtb WHERE CAST("JsonB" -> 'Detail' ->> 'Count' AS INTEGER) >= 200;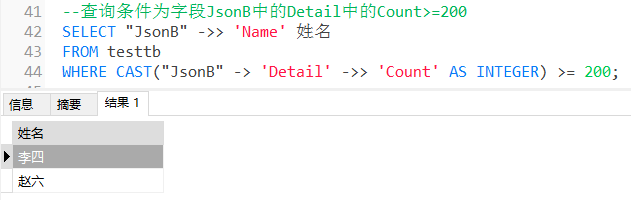
4.3.4-2 此处用到了 PostgreSQL 中的
CAST函数对Count进行转换。聚合查询,查询字段 JsonB 中的 Detail 中的 Count 的最小值、最大值、总和和平均值:
SELECT MIN( CAST ( "JsonB" -> 'Detail' ->> 'Count' AS INTEGER ) ) AS 最小值, MAX( CAST ( "JsonB" -> 'Detail' ->> 'Count' AS INTEGER ) ) AS 最大值, SUM( CAST ( "JsonB" -> 'Detail' ->> 'Count' AS INTEGER ) ) AS 总和, AVG( CAST ( "JsonB" -> 'Detail' ->> 'Count' AS INTEGER ) ) AS 平均值 FROM testtb;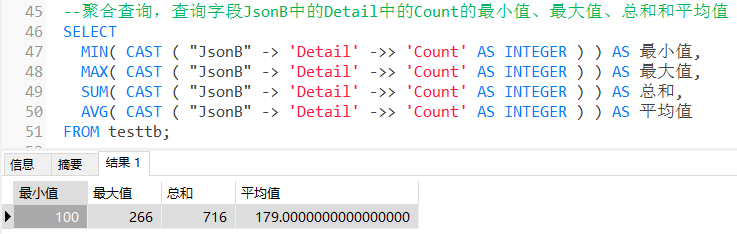
4.3.5 查询字段 JsonB 中的 Detail 中的 Count 的数据类型:
SELECT jsonb_typeof("JsonB" -> 'Detail' -> 'Count') AS 数据类型 FROM testtb;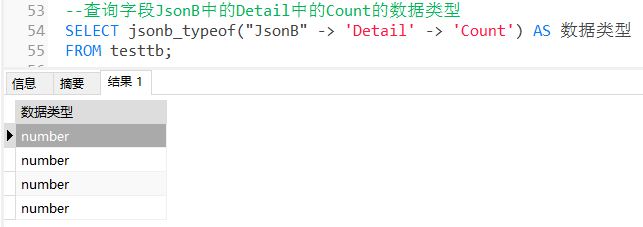
4.3.6 JSON 和 JSONB 操作符
JSON 和 JSONB 操作符 右操作数类型 描述 例子 结果 -> int 获取 json 数组的元素 SELECT '[{"a":"foo"},{"b":"bar"}]'::json -> 1 AS 结果; -> text 通过 key 值获取 json 对象字段 SELECT '{"a": {"b":"foo"}}'::json -> 'a' AS 结果; ->> int 获取 json 数组元素为字符串 SELECT '[1,2,3]'::json ->> 2 AS 结果; 3 ->> text 获取 json 对象字段为字符串 SELECT '{"a":1,"b":2}'::json ->> 'b' AS 结果; 2 #> text[] 在指定路径下获取 json 对象 SELECT '{"a": {"b":{"c": "foo"}}}'::json #> '{a,b}' AS 结果; #>> text[] 在指定路径下获得 json 对象为字符串 SELECT '{"a":[1,2,3],"b":[4,5,6]}'::json #>> '{a,2}' AS 结果; 3 JSONB 操作符 右操作数类型 描述 例子 结果 @> jsonb 在顶层,左边的 json 值包含右边的 json 值 SELECT '{"a":1, "b":2}'::jsonb @> '{"b":2}'::jsonb AS 结果; true <@ jsonb 在顶层,右边的 json 值包含左边的 json 值 SELECT '{"b":2}'::jsonb <@ '{"a":1, "b":2}'::jsonb AS 结果; true || jsonb 将两个 jsonb 值连接成一个新 jsonb 值 SELECT '["a", "b"]'::jsonb || '["c", "d"]'::jsonb AS 结果; ["a", "b", "c", "d"] ? text 判断字符串是否是该 json 的顶级键 SELECT '{"a":1, "b":2}'::jsonb ? 'b' AS 结果; true ?| text[] 判断数组字符串中的任何一个是否作为该 json 的顶级键 SELECT '{"a":1, "b":2, "c":3}'::jsonb ?| array['b', 'c'] AS 结果; true ?& text[] 判断所有的数组字符串是否都作为该 json 顶级键 SELECT '["a", "b"]'::jsonb ?& array['a', 'b'] AS 结果; true - text 从左操作数中删除键/值对或字符串元素 SELECT '{"a": "b"}'::jsonb - 'a' AS 结果; {} - text[] 从左操作数中删除多个键/值对或字符串元素 SELECT '{"a": "b", "c": "d"}'::jsonb - '{a,c}'::text[] AS 结果; {} - integer 删除具有指定索引的数组元素(末尾为负整数) SELECT '["a", "b"]'::jsonb - 1 AS 结果; ["a"] #- text[] 删除具有指定路径的字段或元素 SELECT '["a", {"b":1}]'::jsonb #- '{1,b}' AS 结果; ["a", {}]