介绍
PostgreSQL 说明
本章,我们主要从简介、优势、对比和数据类型这几个方面进行介绍!
1、🍇 PostgreSQL 简介
1.1、常用数据库
在介绍 PostgreSQL 之前,我们可以看下常用的数据库有哪些。
1.1.1、关系型数据库
关系型数据库如下所示:
| 关系型数据库 | ||||
|---|---|---|---|---|
| Oracle | MySql | SqlServer | PostgreSQL | Db2(IBM) |
| ClickHouse(列式存储) | SQLite(嵌入式) | Access | Snowflake | MariaDB |
| Hive | …… | |||
1.1.2、非关系型数据库
非关系型数据库如下所示:
| 非关系型数据库 | ||||
|---|---|---|---|---|
| MongoDB(文档) | ElasticSearch(搜索引擎) | Redis(Key-Value) | Splunk(搜索引擎) | QuestDb |
| Cassandra | Amazon DynamoDB | Databricks | Neo4j | Solr |
| HBase | …… | |||
1.1.3、国产数据库
国产数据库如下所示:
| 国产数据库 | ||||
|---|---|---|---|---|
| OceanBase | TiDB | openGauss | 达梦 | PolarDB |
| GaussDB | 人大金仓 | TDSQL | GBase | AnalyticDB |
| TDengine | …… | |||
1.2、数据库排行
- 全球排行
具体排行如下图所示:
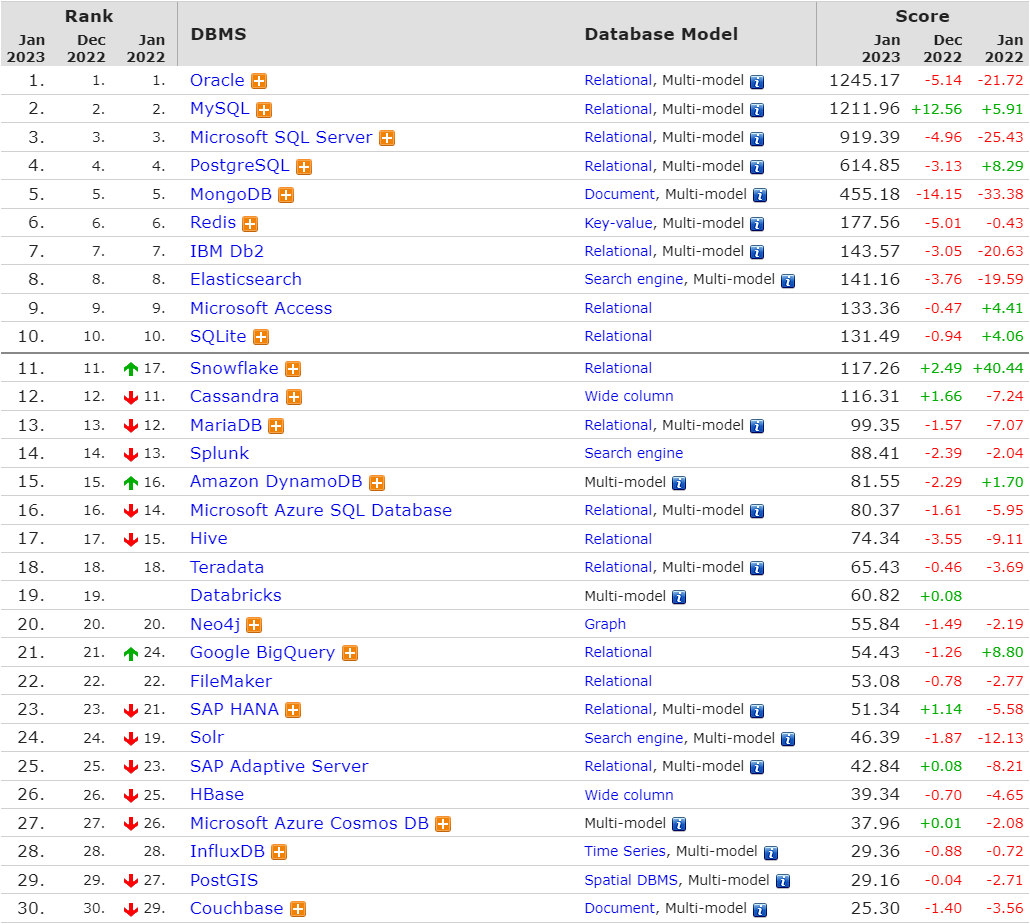
- 国产排行
具体排行如下图所示:
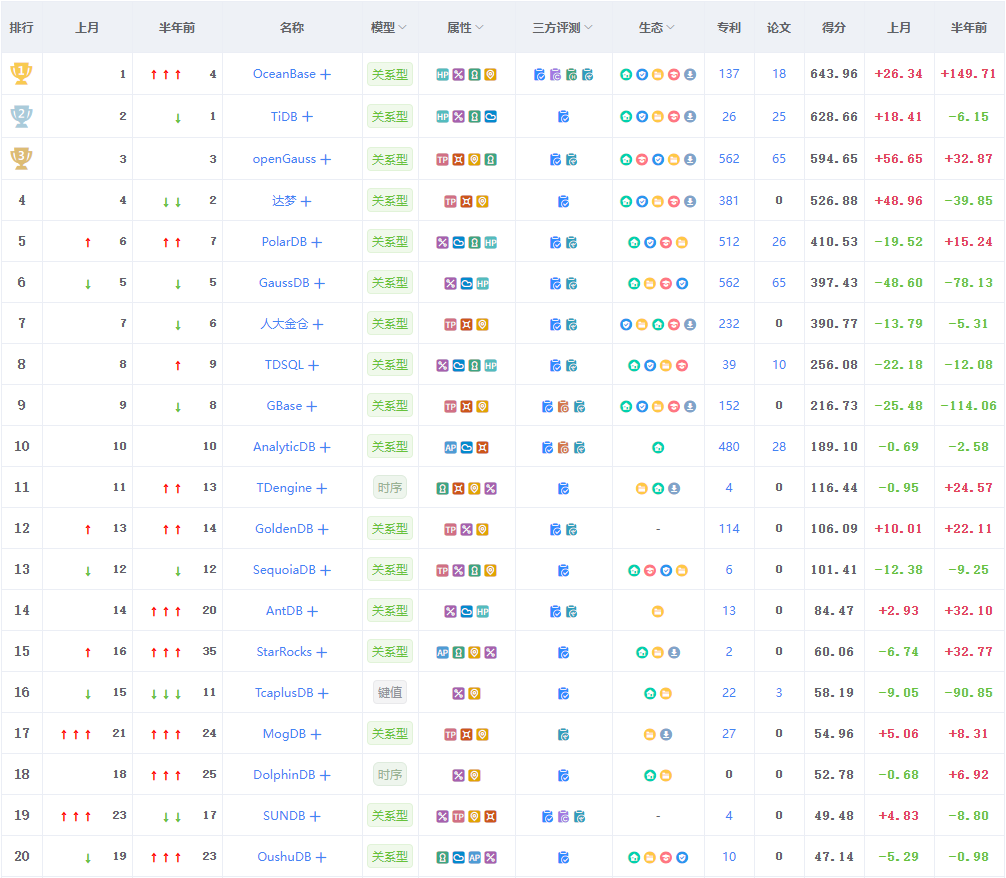
1.3、PostgreSQL 介绍
PostgreSQL 是一个功能强大的开源数据库系统。经过长达 15 年以上的积极开发和不断改进,PostgreSQL 已在可靠性、稳定性、数据一致性等获得了业内极高的声誉。目前 PostgreSQL 可以运行在所有主流操作系统上,包括 Linux、Unix(AIX、BSD、HP-UX、SGI IRIX、Mac OS X、Solaris 和 Tru64)和 Windows。PostgreSQL 是完全的事务安全性数据库,完整地支持外键、联合、视图、触发器和存储过程(并支持多种语言开发存储过程)。它支持了大多数的 SQL:2008 标准的数据类型,包括整型、数值型、布尔型、字节型、字符型、日期型、时间间隔型和时间型,它也支持存储二进制的大对像,包括图片、声音和视频。PostgreSQL 对很多高级开发语言有原生的编程接口,如 C/C++、Java、.Net、Perl、Python、Ruby、Tcl 和 ODBC 以及其他语言等,也包含各种文档。
作为一种企业级数据库,PostgreSQL 以它所具有的各种高级功能而自豪,像多版本并发控制(MVCC)、按时间点恢复(PITR)、表空间、异步复制、嵌套事务、在线热备、复杂查询的规划和优化以及为容错而进行的预写日志等。它支持国际字符集、多字节编码并支持使用当地语言进行排序、大小写处理和格式化等操作。它也在所能管理的大数据量和所允许的大用户量并发访问时间具有完全的高伸缩性。目前已有很多 PostgreSQL 的系统在实际生产环境下管理着超过 4TB 的数据。
1.4、PostgreSQL 发展历史
1977 年: Ingres 于 1977 年首次开发;
1986 年 Michael Stonebraker 和他的同事在 1986 年开发了 Postgres;
1990 年 对 PL/pgSQL 和 ACID 合规性的支持被添加到 PostgreSQL;
2013 年 NYCPUG(纽约市 PostgreSQL 用户组)早在 2013 年就加入了 PgUS(美国 PostgreSQL 协会);
2014 年 PGconf 迎来了 PostgreSQL 用户的新纪元。
1.5、PostgreSQL 相关链接
PostgreSQL 相关链接如下所示:
| 链接说明 | 链接地址 |
|---|---|
| 官方网站 | https://www.postgresql.org |
| 中文社区 | http://www.postgres.cn/v2/home |
| 中文资源网 | https://www.postgreshub.cn |
| 中国开源联盟 PostgreSQL 协会官网 | http://www.postgresqlchina.com |
| 全球数据库排行 | https://db-engines.com/en |
| 国产数据库排行 | https://www.modb.pro/dbRank |
2、🍈 PostgreSQL 优势
2.1、开源省钱
PostgreSQL 数据库是开源的、免费的,而且使用的是类BSD 协议,在使用和二次开发上基本没有限制。
BSD 协议: BSD 开源协议是一个给于使用者很大自由的协议。可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。
2.2、稳定可靠
PostgreSQL 是唯一能做到数据零丢失的开源数据库。目前有报道称国内外有部分银行使用 PostgreSQL 数据库。
2.3、支持广泛
PostgreSQL 数据库支持大量的主流开发语言,包括 C、C++、.Net、Perl、Python、Java、Tcl 以及 PHP 等。
2.4、社区活跃
PostgreSQL 基本上每 3 个月推出一个补丁版本,这意味着已知的 Bug 很快会被修复,有应用场景的需求也会及时得到响应。
2.5、功能强大
PostgreSQL 是架构、语法、数据类型等与 Oracle 最接近的开源数据库;
丰富的数据类型支持(几何、网络地址、XML、JSON、RANGE、数组、复合);
支持复杂的多表 JOIN 查询;
支持窗口函数;
支持函数索引、部分(行)索引、自定义索引、全文索引;
多进程的架构,更加稳定,单机可以支持更高访问量的数据库;
有功能强大、性能优秀的插件,如 PostGIS 是一个空间数据库扩展程序插件,它增加了对地理对象的支持,允许您以 SQL 运行位置查询。
3、🍉 PostgreSQL 对比
3.1、与 Oracle 对比
Oracle 属于商业数据库,PostgreSQL 属于开源数据库;
PostgreSQL 更小巧,可以在内存很小的机器上完美运行起来,如在 512MB 的云主机中,而 Oracle 数据库基本要在数 GB 的云主机中才可以运行起来;
PostgreSQL 具有更丰富的数据类型,支持网络地址类型、XML 类型、JSON 类型、UUID 类型以及数组类型,且有强大的正则表达式函数,如 Where 条件中可以使用正则表达式匹配,也可以使用.Net、Python、Perl 等语言写存储过程等;
PostgreSQL 任何一个环境轻松安装。
3.2、与 MySql 对比
MySql 和 PostgreSQL 都是开源数据库;
PostgreSQL 支持所有主流的多表连接查询的方式,如“Hash JOIN”、“Sort Merge JOIN”等;
PostgreSQL 支持更丰富的数据类型;
PostgreSQL 性能优化工具与度量信息丰富,PostgreSQL 数据库中有大量的性能视图,可以方便地定位问题(比如可以看到正在执行的 SQL,可以通过锁视图看到谁在等待,以及哪条记录被锁定等)。PostgreSQL 中设计了专门架构和进程用于收集性能数据,既有物理 I/O 方面的统计,也有表扫描及索引扫描方面的性能数据;
PostgreSQL 在线操作功能好,PostgreSQL 增加空值列时,本质上只是在系统表上把列定义上,无须对物理结构做更新,这就让 PostgreSQL 在加列时可以做到瞬间完成。PostgreSQL 还支持在线建索引的功能,在创建索引的过程可以不锁更新操作;
PostgreSQL 支持同步复制,从 PostgreSQL9.1 开始,支持同步复制(synchronous replication)功能,通过 Master 和 Slave 之间的复制可以实现零数据丢失的高可用方案;
PostgreSQL 扩展,可以方便地写插件来扩展 PostgreSQL 数据库的功能,支持移动互联网的新功能,如空间索引;
PostgreSQL 更大的数据存储,PostgreSQL 主表采用堆表存放,MySQL 采用索引组织表,能够支持比 MySQL 更大的数据量。
3.3、与 SqlServer 对比
SqlServer 属于商业数据库,PostgreSQL 属于开源数据库;
数据库类型:都属于关系型数据库;
许可证:在 PostgreSQL 许可证下可用,这是开源计划批准的许可证。而 SqlServer 在商业许可下可用;
语言:PostgreSQL 使用 C++开发,SqlServer 使用 C 开发;
操作系统兼容性:PostgreSQL 可在 FreeBSD、HP-UX、Linux、NetBSD、OpenBSD、OS X、Solaris、Unix、Windows 等上运行。SqlServer 可在 Windows 和 Linux 上运行;
安装过程:PostgreSQL 安装过程流畅。SqlServer 安装过程很慢,需要大量下载;
可扩展性:PostgreSQL 通过将表分区和索引放置在不同磁盘文件系统上的不同表空间中,可扩展性得到增强。分片使 SqlServer 能够实现可扩展性;
数据安全:PostgreSQL 身份验证方法,包括轻量级目录访问协议 (LDAP) 和可插入身份验证模块 (PAM),可防止攻击。SqlServer 两个服务器级安全增强功能:Windows 身份验证模式和混合模式,可防止攻击;
并发:PostgreSQL 具有更好的并发管理系统。SqlServer 不发达的并发性,默认情况下依赖于数据锁定来防止同时发生的事务出现错误;
复制:PostgreSQL 支持主从复制,SqlServer 支持快照复制,事务复制,合并复制;
可用性:PostgreSQL 高可用性是通过负载平衡和复制功能实现的。SqlServer 的 Always ON Availability Group 架构高可用,Read Scale Availability Group 架构高可用低;
分区:PostgreSQL 在 EDB 版本中为范围、列表、多级分区和散列分区提供了内置支持,SqlServer 支持表和索引分区;
性能:PostgreSQL 用于同时处理多个事务(几乎没有死锁)的多版本并发控制 (MVCC) 功能可提高性能,SqlServer 内存中联机事务处理 (OLTP) 功能通过使用内存中数据表而不是直接写入磁盘来确保高性能;
存储过程:PostgreSQL 除了标准 SQL 语法之外,还支持各种语言的存储过程。SqlServer 支持 Microsoft .NET 框架支持的语言的存储过程;
索引类型:PostgreSQL 提供提供 B 树、哈希、广义搜索树 (GiST)、空间分区 GiST、广义倒排索引 (GIN) 和块范围索引 (BRIN) 等选项。SqlServer 提供聚集和非聚集索引;
任务调度:PostgreSQL 没有内置调度程序,必须使用外部工具,如 pgAgent、Task Scheduler、cron 等。SqlServer 使用 SQL Server Management Studio 计划的任务;
数据一致性:PostgreSQL 内置逻辑备份实用程序,如 pg_dumpall 和 pg_dump,以及第三方数据一致性工具,如 Amanda、Bacula、Barman 等,都可用。SqlServer 具有三种在线备份模型:简单、完整和大容量日志恢复模型。
4、🍋 PostgreSQL 数据类型
4.1、数值类型
数值类型由 2 字节、4 字节或 8 字节的整数以及 4 字节或 8 字节的浮点数和可选精度的十进制数组成。
| 类型名称 | 存储长度 | 描述 | 范围 |
|---|---|---|---|
| smallint | 2 字节 | 小范围整数 | -32768 到 +32767 |
| integer | 4 字节 | 常用的整数 | -2147483648 到 +2147483647 |
| bigint | 8 字节 | 大范围整数 | -9223372036854775808 到 +9223372036854775807 |
| decimal | 可变长 | 用户指定的精度,精确 | 小数点前 131072 位;小数点后 16383 位 |
| numeric | 可变长 | 用户指定的精度,精确 | 小数点前 131072 位;小数点后 16383 位 |
| real | 4 字节 | 可变精度,不精确 | 6 位十进制数字精度 |
| double precision | 8 字节 | 可变精度,不精确 | 15 位十进制数字精度 |
| smallserial | 2 字节 | 自增的小范围整数 | 1 到 32767 |
| serial | 4 字节 | 自增整数 | 1 到 2147483647 |
| bigserial | 8 字节 | 自增的大范围整数 | 1 到 9223372036854775807 |
4.2、货币类型
money 类型存储带有固定小数精度的货币金额。
numeric、int 和 bigint 类型的值可以转换为 money,不建议使用浮点数来处理处理货币类型,因为存在舍入错误的可能性。
| 类型名称 | 存储容量 | 描述 | 范围 |
|---|---|---|---|
| money | 8 字节 | 货币金额 | -92233720368547758.08 到 +92233720368547758.07 |
4.3、字符类型
下表列出了 PostgreSQL 所支持的字符类型:
| 序号 | 类型名字和描述 |
|---|---|
| 1 | character varying(n), varchar(n) 变长,有长度限制 |
| 2 | character(n), char(n) f 定长,不足补空白 |
| 3 | text 变长,无长度限制 |
4.4、日期/时间类型
下表列出了 PostgreSQL 支持的日期和时间类型:
| 类型名字 | 存储空间 | 描述 | 最低值 | 最高值 | 分辨率 |
|---|---|---|---|---|---|
| timestamp [ (p) ] [ without time zone ] | 8 字节 | 日期和时间(无时区) | 4713 BC | 294276 AD | 1 毫秒 / 14 位 |
| timestamp [ (p) ] with time zone | 8 字节 | 日期和时间,有时区 | 4713 BC | 294276 AD | 1 毫秒 / 14 位 |
| date | 4 字节 | 只用于日期 | 4713 BC | 5874897 AD | 1 天 |
| time [ (p) ] [ without time zone ] | 8 字节 | 只用于一日内时间 | 00:00:00 | 24:00:00 | 1 毫秒 / 14 位 |
| time [ (p) ] with time zone | 12 字节 | 只用于一日内时间,带时区 | 00:00:00+1459 | 24:00:00-1459 | 1 毫秒 / 14 位 |
| interval [ fields ] [ (p) ] | 12 字节 | 时间间隔 | -178000000 年 | 178000000 年 | 1 毫秒 / 14 位 |
4.5、布尔类型
PostgreSQL 支持标准的 boolean 数据类型。
boolean 有"true"(真)或"false"(假)两个状态, 第三种"unknown"(未知)状态,用 NULL 表示。
| 类型名称 | 存储格式 | 描述 |
|---|---|---|
| boolean | 1 字节 | true/false |
4.6、枚举类型
枚举类型是一个包含静态和值的有序集合的数据类型。
PostgtesSQL 中的枚举类型类似于 C 语言中的 enum 类型。
与其他类型不同的是枚举类型需要使用 CREATE TYPE 命令创建。
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
创建一周中的几天,如下所示:
CREATE TYPE week AS ENUM ('Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun');
就像其他类型一样,一旦创建,枚举类型可以用于表和函数定义。
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
CREATE TABLE person (
name text,
current_mood mood
);
INSERT INTO person VALUES ('Moe', 'happy');
SELECT * FROM person WHERE current_mood = 'happy';
name | current_mood
------+--------------
Moe | happy
(1 row)
4.7、几何类型
几何数据类型表示二维的平面物体。
下表列出了 PostgreSQL 支持的几何类型。
最基本的类型:点。它是其它类型的基础。
| 类型名字 | 存储空间 | 说明 | 表现形式 |
|---|---|---|---|
| point | 16 字节 | 平面中的点 | (x,y) |
| line | 32 字节 | (无穷)直线(未完全实现) | ((x1,y1),(x2,y2)) |
| lseg | 32 字节 | (有限)线段 | ((x1,y1),(x2,y2)) |
| box | 32 字节 | 矩形 | ((x1,y1),(x2,y2)) |
| path | 16+16n 字节 | 闭合路径(与多边形类似) | ((x1,y1),...) |
| path | 16+16n 字节 | 开放路径 | [(x1,y1),...] |
| polygon | 40+16n 字节 | 多边形(与闭合路径相似) | ((x1,y1),...) |
| circle | 24 字节 | 圆 | <(x,y),r> (圆心和半径) |
4.8、网络地址类型
PostgreSQL 提供用于存储 IPv4 、IPv6 、MAC 地址的数据类型。
用这些数据类型存储网络地址比用纯文本类型好, 因为这些类型提供输入错误检查和特殊的操作和功能。
| 类型名字 | 存储空间 | 描述 |
|---|---|---|
| cidr | 7 或 19 字节 | IPv4 或 IPv6 网络 |
| inet | 7 或 19 字节 | IPv4 或 IPv6 主机和网络 |
| macaddr | 6 字节 | MAC 地址 |
4.9、位串类型
位串就是一串 1 和 0 的字符串。它们可以用于存储和直观化位掩码。 我们有两种 SQL 位类型:bit(n) 和 bit varying(n), 这里的 n 是一个正整数。
bit 类型的数据必须准确匹配长度 n, 试图存储短些或者长一些的数据都是错误的。bit varying 类型数据是最长 n 的变长类型;更长的串会被拒绝。 写一个没有长度的 bit 等效于 bit(1), 没有长度的 bit varying 意思是没有长度限制。
4.10、文本搜索类型
全文检索即通过自然语言文档的集合来找到那些匹配一个查询的检索。
PostgreSQL 提供了两种数据类型用于支持全文检索:
| 序号 | 类型名字和描述 |
|---|---|
| 1 | tsvectortsvector 的值是一个无重复值的 lexemes 排序列表, 即一些同一个词的不同变种的标准化。 |
| 2 | tsquerytsquery 存储用于检索的词汇,并且使用布尔操作符 &(AND),|(OR)和!(NOT) 来组合它们,括号用来强调操作符的分组。 |
4.11、UUID 类型
uuid 数据类型用来存储 RFC 4122,ISO/IEF 9834-8:2005 以及相关标准定义的通用唯一标识符(UUID)。 (一些系统认为这个数据类型为全球唯一标识符,或 GUID。) 这个标识符是一个由算法产生的 128 位标识符,使它不可能在已知使用相同算法的模块中和其他方式产生的标识符相同。 因此,对分布式系统而言,这种标识符比序列能更好的提供唯一性保证,因为序列只能在单一数据库中保证唯一。
UUID 被写成一个小写十六进制数字的序列,由分字符分成几组, 特别是一组 8 位数字+3 组 4 位数字+一组 12 位数字,总共 32 个数字代表 128 位, 一个这种标准的 UUID 例子如下:
a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11
4.12、XML 类型
xml 数据类型可以用于存储 XML 数据。 将 XML 数据存到 text 类型中的优势在于它能够为结构良好性来检查输入值, 并且还支持函数对其进行类型安全性检查。 要使用这个数据类型,编译时必须使用 configure --with-libxml。
xml 可以存储由 XML 标准定义的格式良好的"文档", 以及由 XML 标准中的 XMLDecl? content 定义的"内容"片段, 大致上,这意味着内容片段可以有多个顶级元素或字符节点。 xmlvalue IS DOCUMENT 表达式可以用来判断一个特定的 xml 值是一个完整的文件还是内容片段。
创建 XML 值
使用函数 xmlparse: 来从字符数据产生 xml 类型的值:
XMLPARSE (DOCUMENT '<?xml version="1.0"?><book><title>Manual</title><chapter>...</chapter></book>')
XMLPARSE (CONTENT 'abc<foo>bar</foo><bar>foo</bar>')
4.13、JSON 类型
json 数据类型可以用来存储 JSON(JavaScript Object Notation)数据, 这样的数据也可以存储为 text,但是 json 数据类型更有利于检查每个存储的数值是可用的 JSON 值。
此外还有相关的函数来处理 json 数据:
| 实例 | 实例结果 |
|---|---|
| array_to_json('{\{1,5\},\{99,100\}}'::int[]) | [[1,5],[99,100]] |
| row_to_json(row(1,'foo')) | {"f1":1,"f2":"foo"} |
4.14、数组类型
PostgreSQL 允许将字段定义成变长的多维数组。
数组类型可以是任何基本类型或用户定义类型,枚举类型或复合类型。
声明数组
创建表的时候,我们可以声明数组,方式如下:
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
pay_by_quarter 为一维整型数组、schedule 为二维文本类型数组。
我们也可以使用 "ARRAY" 关键字,如下所示:
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer ARRAY[4],
schedule text[][]
);
插入值
插入值使用花括号 {},元素在 {} 使用逗号隔开:
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
INSERT INTO sal_emp
VALUES ('Carol',
'{20000, 25000, 25000, 25000}',
'{{"breakfast", "consulting"}, {"meeting", "lunch"}}');
访问数组
现在我们可以在这个表上运行一些查询。
首先,我们演示如何访问数组的一个元素。 这个查询检索在第二季度薪水变化的雇员名:
SELECT name FROM sal_emp WHERE pay_by_quarter[1] <> pay_by_quarter[2];
name
-------
Carol
(1 row)
数组的下标数字是写在方括弧内的。
修改数组
我们可以对数组的值进行修改:
UPDATE sal_emp SET pay_by_quarter = '{25000,25000,27000,27000}'
WHERE name = 'Carol';
或者使用 ARRAY 构造器语法:
UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000]
WHERE name = 'Carol';
数组中检索
要搜索一个数组中的数值,你必须检查该数组的每一个值。
比如:
SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR
pay_by_quarter[2] = 10000 OR
pay_by_quarter[3] = 10000 OR
pay_by_quarter[4] = 10000;
另外,你可以用下面的语句找出数组中所有元素值都等于 10000 的行:
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter);
或者,可以使用 generate_subscripts 函数。例如:
SELECT * FROM
(SELECT pay_by_quarter,
generate_subscripts(pay_by_quarter, 1) AS s
FROM sal_emp) AS foo
WHERE pay_by_quarter[s] = 10000;
4.15、复合类型
复合类型表示一行或者一条记录的结构; 它实际上只是一个字段名和它们的数据类型的列表。PostgreSQL 允许像简单数据类型那样使用复合类型。比如,一个表的某个字段可以声明为一个复合类型。
声明复合类型
下面是两个定义复合类型的简单例子:
CREATE TYPE complex AS (
r double precision,
i double precision
);
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
语法类似于 CREATE TABLE,只是这里只可以声明字段名字和类型。
定义了类型,我们就可以用它创建表:
CREATE TABLE on_hand (
item inventory_item,
count integer
);
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
复合类型值输入
要以文本常量书写复合类型值,在圆括弧里包围字段值并且用逗号分隔他们。 你可以在任何字段值周围放上双引号,如果值本身包含逗号或者圆括弧, 你必须用双引号括起。
复合类型常量的一般格式如下:
'( val1 , val2 , ... )'
一个例子是:
'("fuzzy dice",42,1.99)'
访问复合类型
要访问复合类型字段的一个域,我们写出一个点以及域的名字, 非常类似从一个表名字里选出一个字段。实际上,因为实在太像从表名字中选取字段, 所以我们经常需要用圆括弧来避免分析器混淆。比如,你可能需要从 on_hand 例子表中选取一些子域,像下面这样:
SELECT item.name FROM on_hand WHERE item.price > 9.99;
这样将不能工作,因为根据 SQL 语法,item 是从一个表名字选取的, 而不是一个字段名字。你必须像下面这样写:
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
或者如果你也需要使用表名字(比如,在一个多表查询里),那么这么写:
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
现在圆括弧对象正确地解析为一个指向 item 字段的引用,然后就可以从中选取子域。
4.16、范围类型
范围数据类型代表着某一元素类型在一定范围内的值。
例如,timestamp 范围可能被用于代表一间会议室被预定的时间范围。
PostgreSQL 内置的范围类型有:
int4range — integer 的范围
int8range —bigint 的范围
numrange —numeric 的范围
tsrange —timestamp without time zone 的范围
tstzrange —timestamp with time zone 的范围
daterange —date 的范围
此外,你可以定义你自己的范围类型。
CREATE TABLE reservation (room int, during tsrange);
INSERT INTO reservation VALUES
(1108, '[2010-01-01 14:30, 2010-01-01 15:30)');
-- 包含
SELECT int4range(10, 20) @> 3;
-- 重叠
SELECT numrange(11.1, 22.2) && numrange(20.0, 30.0);
-- 提取上边界
SELECT upper(int8range(15, 25));
-- 计算交叉
SELECT int4range(10, 20) * int4range(15, 25);
-- 范围是否为空
SELECT isempty(numrange(1, 5));
范围值的输入必须遵循下面的格式:
(下边界,上边界) (下边界,上边界] [下边界,上边界) [下边界,上边界] 空
圆括号或者方括号显示下边界和上边界是不包含的还是包含的。注意最后的格式是 空,代表着一个空的范围(一个不含有值的范围)。
-- 包括3,不包括7,并且包括二者之间的所有点
SELECT '[3,7)'::int4range;
-- 不包括3和7,但是包括二者之间所有点
SELECT '(3,7)'::int4range;
-- 只包括单一值4
SELECT '[4,4]'::int4range;
-- 不包括点(被标准化为‘空’)
SELECT '[4,4)'::int4range;
4.17、对象标识符类型
PostgreSQL 在内部使用对象标识符(OID)作为各种系统表的主键。
同时,系统不会给用户创建的表增加一个 OID 系统字段(除非在建表时声明了 WITH OIDS 或者配置参数 default_with_oids 设置为开启)。oid 类型代表一个对象标识符。除此以外 oid 还有几个别名:regproc, regprocedure, regoper, regoperator, regclass, regtype, regconfig, 和 regdictionary。
| 类型名字 | 引用 | 描述 | 数值例子 |
|---|---|---|---|
| oid | 任意 | 数字化的对象标识符 | 564182 |
| regproc | pg_proc | 函数名字 | sum |
| regprocedure | pg_proc | 带参数类型的函数 | sum(int4) |
| regoper | pg_operator | 操作符名 | + |
| regoperator | pg_operator | 带参数类型的操作符 | (integer,integer) 或 -(NONE,integer) |
| regclass | pg_class | 关系名 | pg_type |
| regtype | pg_type | 数据类型名 | integer |
| regconfig | pg_ts_config | 文本搜索配置 | english |
| regdictionary | pg_ts_dict | 文本搜索字典 | simple |
4.18、伪类型
PostgreSQL 类型系统包含一系列特殊用途的条目, 它们按照类别来说叫做伪类型。伪类型不能作为字段的数据类型, 但是它可以用于声明一个函数的参数或者结果类型。 伪类型在一个函数不只是简单地接受并返回某种 SQL 数据类型的情况下很有用。
下表列出了所有的伪类型:
| 类型名字 | 描述 |
|---|---|
| any | 表示一个函数接受任何输入数据类型。 |
| anyelement | 表示一个函数接受任何数据类型。 |
| anyarray | 表示一个函数接受任意数组数据类型。 |
| anynonarray | 表示一个函数接受任意非数组数据类型。 |
| anyenum | 表示一个函数接受任意枚举数据类型。 |
| anyrange | 表示一个函数接受任意范围数据类型。 |
| cstring | 表示一个函数接受或者返回一个空结尾的 C 字符串。 |
| internal | 表示一个函数接受或者返回一种服务器内部的数据类型。 |
| language_handler | 一个过程语言调用处理器声明为返回 language_handler。 |
| fdw_handler | 一个外部数据封装器声明为返回 fdw_handler。 |
| record | 标识一个函数返回一个未声明的行类型。 |
| trigger | 一个触发器函数声明为返回 trigger。 |
| void | 表示一个函数不返回数值。 |
| opaque | 一个已经过时的类型,以前用于所有上面这些用途。 |